83.5 JSON에서 숫자 파싱하기
지금까지 문자열을 파싱했으니 이번에는 숫자를 파싱해보겠습니다. 그림 83‑9는 JSON에서 숫자를 파싱하는 과정입니다.
다음과 같이 example.json 파일에 출시 연도 Year, 상영 시간Runtime, IMDB 평점 imdbRating키와 값을 추가합니다. 파일은 GitHub 저장소의 Unit 83/83.5/json/json 폴더에 들어있습니다). 참고로 IMDB는 영화 전문 데이터베이스 사이트입니다. http://www.imdb.com).
example.json
{ "Title": "Inception", "Year": 2010, "Runtime": 148, "Genre": "Sci-Fi", "Director": "Christopher Nolan", "Actors": [ "Leonardo DiCaprio", "Joseph Gordon-Levitt", "Ellen Page", "Tom Hardy", "Ken Watanabe" ], "imdbRating": 8.8 }
JSON에서 숫자 값은 "로 묶지 않으며 숫자가 그대로 들어갑니다. 따라서 이 특징을 이용하여 숫자를 처리해보겠습니다.
앞에서 만든 소스 코드의 parseJSON 함수에서 case '0': case '1': case '2': case '3': case '4': case '5': case '6': case '7': case '8': case '9': case '-':를 추가합니다.
void parseJSON(char *doc, int size, JSON *json) // JSON 파싱 함수 { int tokenIndex = 0; // 토큰 인덱스 int pos = 0; // 문자 검색 위치를 저장하는 변수 if (doc[pos] != '{') // 문서의 시작이 {인지 검사 return; pos++; // 다음 문자로 while (pos < size) // 문서 크기만큼 반복 { switch (doc[pos]) // 문자의 종류에 따라 분기 { case '"': // 문자가 "이면 문자열 { // 생략... } break; case '[': // 문자가 [이면 배열 { // 생략... } break; case '0': case '1': case '2': case '3': case '4': case '5': // 문자가 숫자이면 case '6': case '7': case '8': case '9': case '-': // -는 음수일 때 { // 문자열의 시작 위치를 구함 char *begin = doc + pos; char *end; char *buffer; // 문자열의 끝 위치를 구함. ,가 나오거나 end = strchr(doc + pos, ','); if (end == NULL) { // } 가 나오면 문자열이 끝남 end = strchr(doc + pos, '}'); if (end == NULL) // }가 없으면 잘못된 문법이므로 break; // 반복을 종료 } int stringLength = end - begin; // 문자열의 실제 길이는 끝 위치 - 시작 위치 // 문자열 길이 + NULL 공간만큼 메모리 할당 buffer = malloc(stringLength + 1); // 할당한 메모리를 0으로 초기화 memset(buffer, 0, stringLength + 1); // 문서에서 문자열을 버퍼에 저장 // 문자열 시작 위치에서 문자열 길이만큼만 복사 memcpy(buffer, begin, stringLength); // 토큰 종류는 숫자 json->tokens[tokenIndex].type = TOKEN_NUMBER; // 문자열을 숫자로 변환하여 토큰에 저장 json->tokens[tokenIndex].number = atof(buffer); free(buffer); // 버퍼 해제 tokenIndex++; // 토큰 인덱스 증가 pos = pos + stringLength + 1; // 현재 위치 + 문자열 길이 + , 또는 }(+ 1) } break; } pos++; // 다음 문자로 } }
JSON 문서는 텍스트 문서이므로 안에 저장된 숫자는 사람이 보기에는 숫자이지만 실제로는 문자열입니다. 따라서 case '0':과 같이 숫자를 문자로 처리해야 합니다. 숫자가 여러 자리라 하더라도 첫 번째 문자만 숫자이면 나머지 자리도 숫자로 처리하면 됩니다. 그리고 숫자가 음수일 수도 있으므로 case '-':와 같이 -도 함께 처리해줍니다.
case '0': case '1': case '2': case '3': case '4': case '5': // 문자가 숫자이면 case '6': case '7': case '8': case '9': case '-': // -는 음수일 때 {
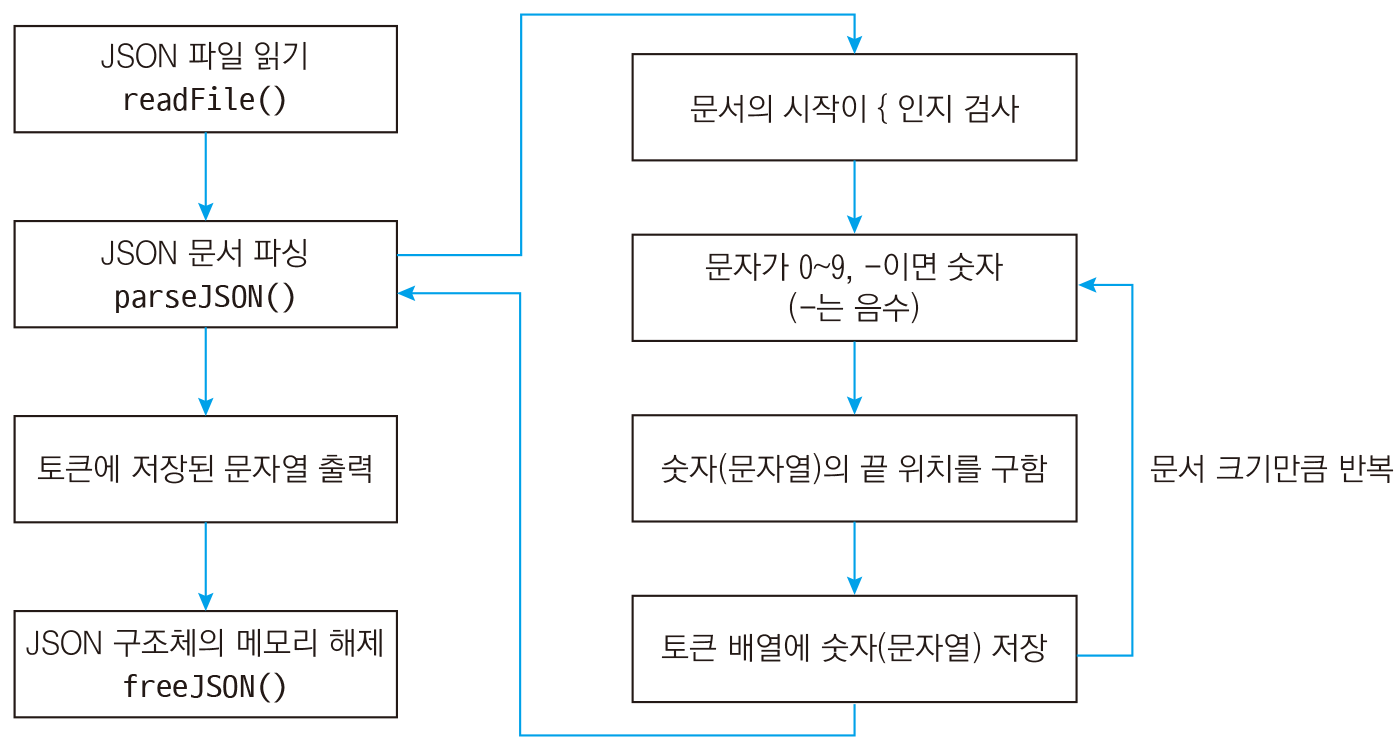
다음은 JSON 문서에서 숫자의 시작 부분을 찾는 모습입니다.

숫자는 앞에 "가 없으므로 doc + pos가 시작 위치입니다. 마찬가지로 뒤에 "가 없으므로 , 또는 }가 나오면 숫자의 끝으로 봅니다. 만약 , 와 } 둘다 없으면 잘못된 문법이므로 반복을 종료합니다.
// 문자열의 시작 위치를 구함 char *begin = doc + pos; char *end; char *buffer; // 문자열의 끝 위치를 구함. ,가 나오거나 end = strchr(doc + pos, ','); if (end == NULL) { // } 가 나오면 문자열이 끝남 end = strchr(doc + pos, '}'); if (end == NULL) // }가 없으면 잘못된 문법이므로 break; // 반복을 종료 }
다음은 JSON 문서에서 숫자의 시작 위치 begin과 끝 위치 end를 구하는 과정입니다.
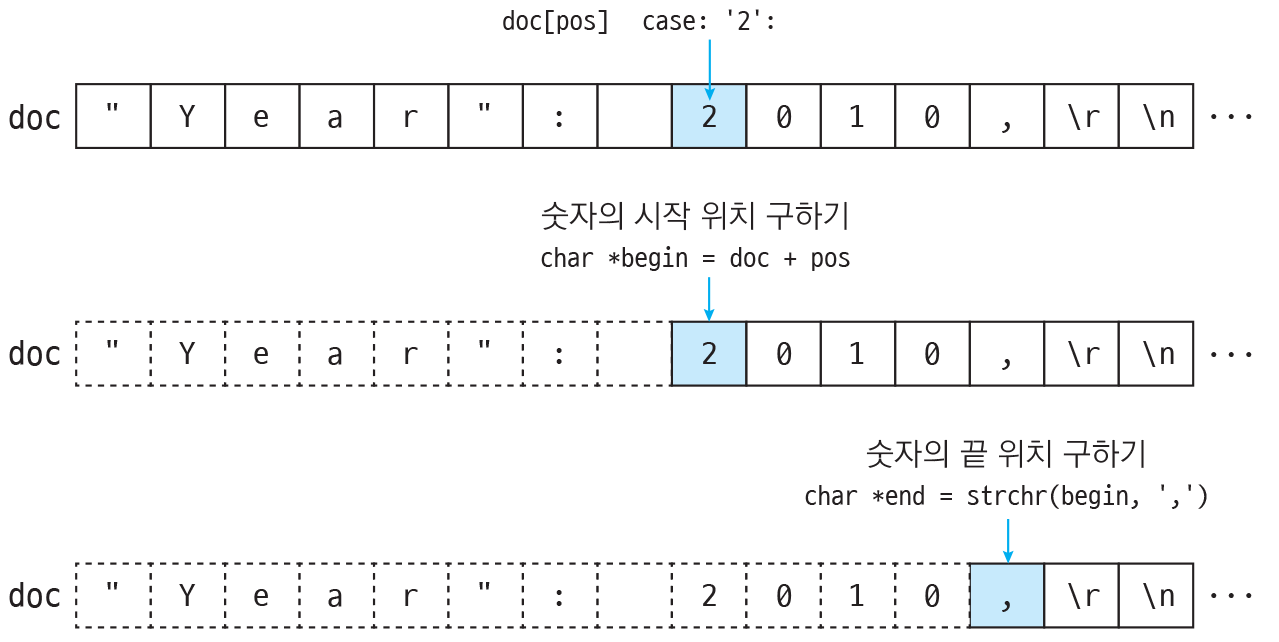
문자열의 실제 길이를 구한 뒤 버퍼에 문자열의 길이 stringLength + NULL 공간만큼 메모리를 할당하고, 0으로 초기화합니다.
int stringLength = end - begin; // 문자열의 실제 길이는 끝 위치 - 시작 위치 // 문자열 길이 + NULL 공간만큼 메모리 할당 buffer = malloc(stringLength + 1); // 할당한 메모리를 0으로 초기화 memset(buffer, 0, stringLength + 1);
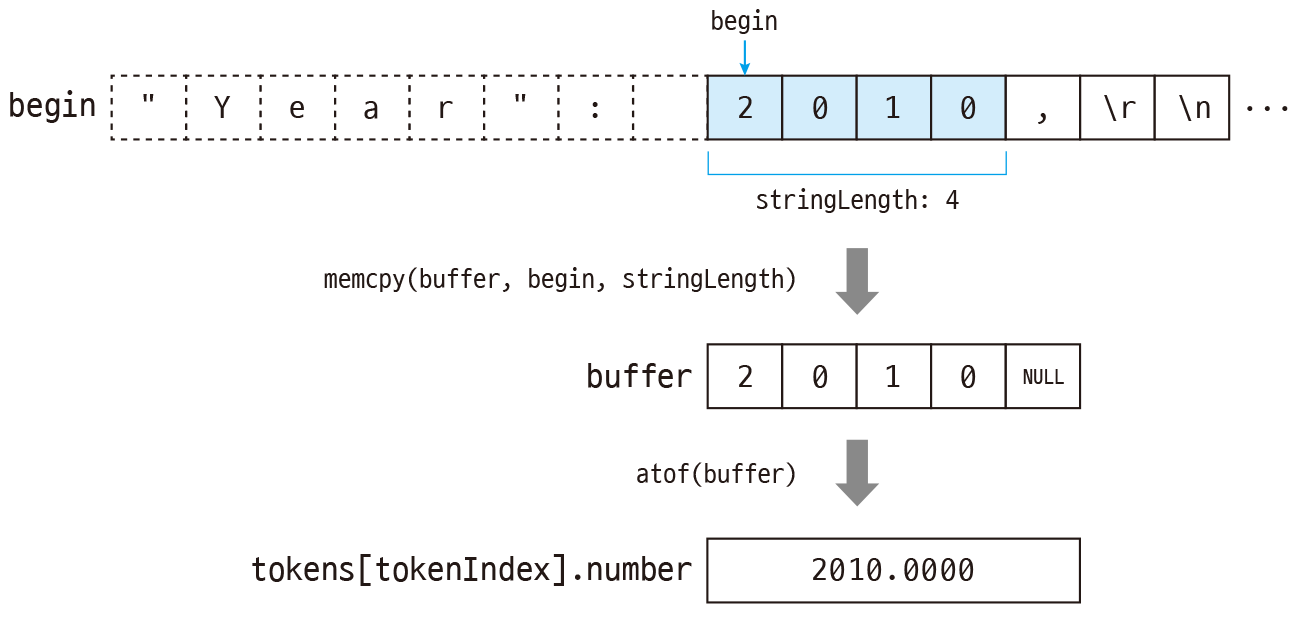
이제 문서의 문자열을 버퍼에 저장합니다. 단, 문자열을 그대로 사용할 수는 없으므로 atof 함수로 문자열(buffer)을 숫자로 변환하여 토큰에 저장합니다. 또한, 토큰 종류에는 TOKEN_NUMBER를 지정합니다.
모든 처리가 끝났으면 버퍼를 해제하고, 토큰 인덱스를 증가시킵니다. 그리고 pos에는 문자열 길이와 " 또는 }의 크기 1을 더해서 다음 문자열을 처리할 수 있도록 만듭니다.
// 문서에서 문자열을 버퍼에 저장 // 문자열 시작 위치에서 문자열 길이만큼만 복사 memcpy(buffer, begin, stringLength); // 토큰 종류는 숫자 json->tokens[tokenIndex].type = TOKEN_NUMBER; // 문자열을 숫자로 변환하여 토큰에 저장 json->tokens[tokenIndex].number = atof(buffer); free(buffer); // 버퍼 해제 tokenIndex++; // 토큰 인덱스 증가 pos = pos + stringLength + 1; // 현재 위치 + 문자열 길이 + , 또는 }(+ 1) } break;
다음은 JSON 문서에서 숫자를 토큰에 저장하는 과정입니다.
이제 main 함수에서 숫자도 함께 출력해보겠습니다(전체 파일은 GitHub 저장소의 Unit 83/83.5/json/json 폴더에 들어있습니다).
json.c
int main() { int size; // 문서 크기 // 파일에서 JSON 문서를 읽음, 문서 크기를 구함 char *doc = readFile("example.json", &size); if (doc == NULL) return -1; JSON json = { 0, }; // JSON 구조체 변수 선언 및 초기화 parseJSON(doc, size, &json); // JSON 문서 파싱 printf("Title: %s\n", json.tokens[1].string); // 토큰에 저장된 문자열 출력(Title) printf("Year: %d\n", (int)json.tokens[3].number); // 토큰에 저장된 숫자 출력(Year) printf("Runtime: %d\n", (int)json.tokens[5].number); // 토큰에 저장된 숫자 출력(Runtime) printf("Genre: %s\n", json.tokens[7].string); // 토큰에 저장된 문자열 출력(Genre) printf("Director: %s\n", json.tokens[9].string); // 토큰에 저장된 문자열 출력(Director) printf("Actors:\n"); printf(" %s\n", json.tokens[11].string); // 토큰에 저장된 문자열 출력(Actors 배열의 요소) printf(" %s\n", json.tokens[12].string); // 토큰에 저장된 문자열 출력(Actors 배열의 요소) printf(" %s\n", json.tokens[13].string); // 토큰에 저장된 문자열 출력(Actors 배열의 요소) printf(" %s\n", json.tokens[14].string); // 토큰에 저장된 문자열 출력(Actors 배열의 요소) printf(" %s\n", json.tokens[15].string); // 토큰에 저장된 문자열 출력(Actors 배열의 요소) printf("imdbRating: %f\n", json.tokens[17].number); // 토큰에 저장된 숫자 출력(imdbRating) freeJSON(&json); // json 안에 할당된 동적 메모리 해제 free(doc); // 문서 동적 메모리 해제 return 0; }
Visual Studio에서 Ctrl+F5 키를 눌러서 프로그램을 실행하면 다음과 같이 JSON 문서의 Year, Runtime, imdbRatings도 함께 출력됩니다.
실행 결과
Title: Inception Year: 2010 Runtime: 148 Genre: Sci-Fi Director: Christopher Nolan Actors: Leonardo DiCaprio Joseph Gordon-Levitt Ellen Page Tom Hardy Ken Watanabe imdbRating: 8.800000
json.tokens에서 숫자를 가져왔을 때 Year, Runtime은 (int)를 사용하여 정수로 변환했고, imdbRating은 실수를 그대로 출력했습니다. JSON 문서의 숫자는 정수로 사용하고 싶으면 앞에 (int)를 붙여서 자료형 변환을 해주고, 실수로 사용하고 싶으면 그대로 출력하면 됩니다.