83.4 JSON에서 문자열 배열 파싱하기
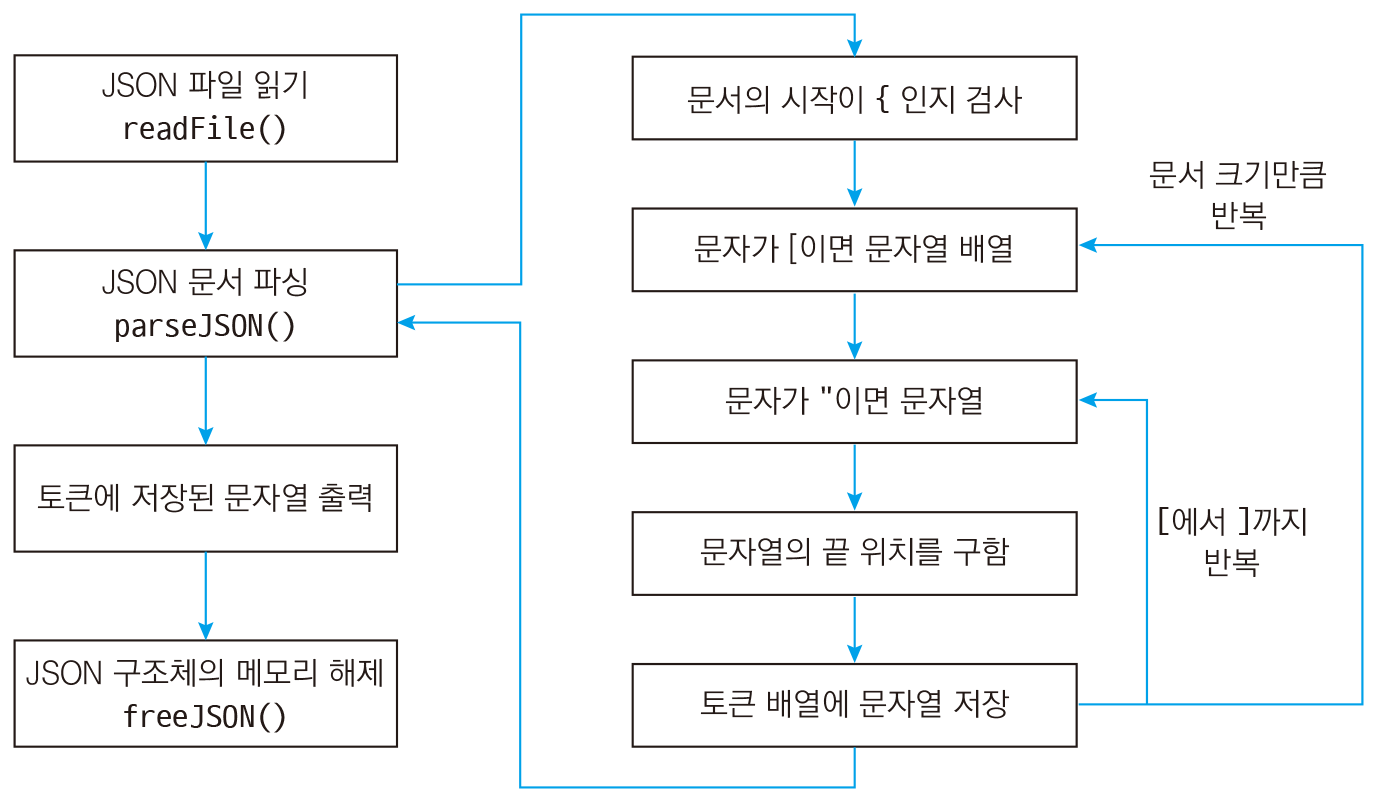
이번에는 문자열 배열을 파싱해보겠습니다. 그림 83‑5는 JSON에서 문자열 배열을 파싱하는 과정입니다.
다음과 같이 example.json 파일에 출연 배우 명단을 Actors 키로 추가해봅시다(파일은 GitHub 저장소의 Unit 83/83.4/json/json 폴더에 들어있습니다).
example.json
{ "Title": "Inception", "Genre": "Sci-Fi", "Director": "Christopher Nolan", "Actors": [ "Leonardo DiCaprio", "Joseph Gordon-Levitt", "Ellen Page", "Tom Hardy", "Ken Watanabe" ] }
JSON 문서에서 문자열 배열은 [ ]안에 "로 묶은 문자열이 콤마로 구분되어 들어있습니다. 따라서 이 특징을 이용하여 문자열 배열을 처리해보겠습니다.
앞에서 만든 소스 코드의 parseJSON 함수에서 case '[':를 추가합니다.
void parseJSON(char *doc, int size, JSON *json) // JSON 파싱 함수 { int tokenIndex = 0; // 토큰 인덱스 int pos = 0; // 문자 검색 위치를 저장하는 변수 if (doc[pos] != '{') // 문서의 시작이 {인지 검사 return; pos++; // 다음 문자로 while (pos < size) // 문서 크기만큼 반복 { switch (doc[pos]) // 문자의 종류에 따라 분기 { case '"': // 문자가 "이면 문자열 { // 생략... } break; case '[': // 문자가 [이면 배열 { pos++; // 다음 문자로 while (doc[pos] != ']') // 닫는 ]가 나오면 반복 종료 { // 여기서는 문자열 배열만 처리 if (doc[pos] == '"') // 문자가 "이면 문자열 { // 문자열의 시작 위치를 구함. 맨 앞의 "를 제외하기 위해 + 1 char *begin = doc + pos + 1; // 문자열의 끝 위치를 구함. 다음 "의 위치 char *end = strchr(begin, '"'); if (end == NULL) // "가 없으면 잘못된 문법이므로 break; // 반복을 종료 int stringLength = end - begin; // 문자열의 실제 길이는 끝 위치 - 시작 위치 // 토큰 배열에 문자열 저장 // 토큰 종류는 문자열 json->tokens[tokenIndex].type = TOKEN_STRING; // 문자열 길이 + NULL 공간만큼 메모리 할당 json->tokens[tokenIndex].string = malloc(stringLength + 1); // 현재 문자열은 배열의 요소 json->tokens[tokenIndex].isArray = true; // 할당한 메모리를 0으로 초기화 memset(json->tokens[tokenIndex].string, 0, stringLength + 1); // 문서에서 문자열을 토큰에 저장 // 문자열 시작 위치에서 문자열 길이만큼만 복사 memcpy(json->tokens[tokenIndex].string, begin, stringLength); tokenIndex++; // 토큰 인덱스 증가 pos = pos + stringLength + 1; // 현재 위치 + 문자열 길이 + "(+ 1) } pos++; // 다음 문자로 } } break; } pos++; // 다음 문자로 } }
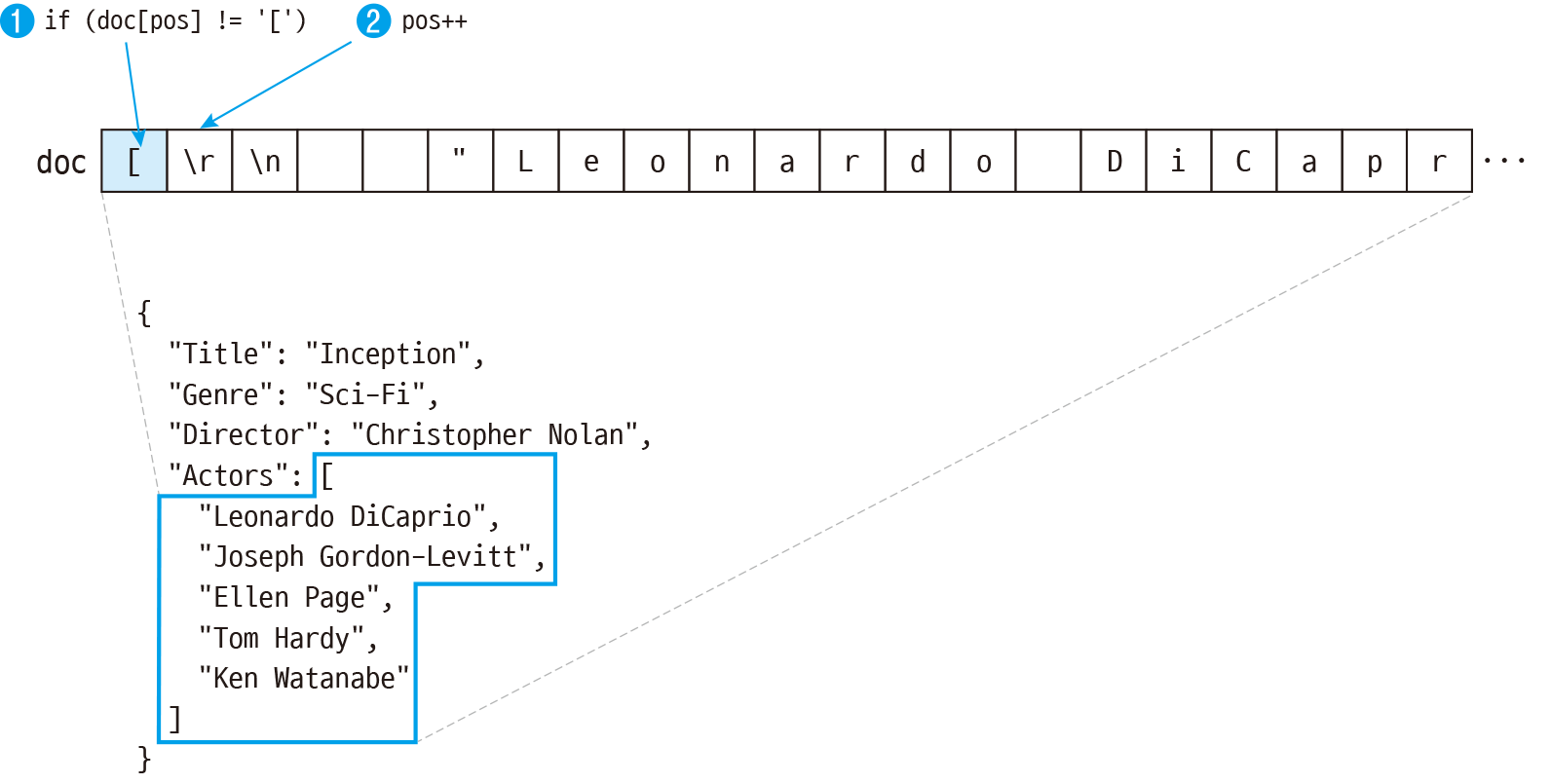
doc[pos]에 들어있는 문자가 [이면 배열입니다. 먼저 pos를 1 증가시켜서 [ 다음 문자를 처리하면서 ]가 나올 때까지 while 루프를 반복합니다.
case '[': // 문자가 [이면 배열 { pos++; // 다음 문자로 while (doc[pos] != ']') // 닫는 ]가 나오면 반복 종료 { // 생략... pos++; // 다음 문자로 } }
즉, 그림 83‑6와 같이 JSON 문서에서 배열의 시작 부분을 찾고, 다음 문자를 처리하게 됩니다.
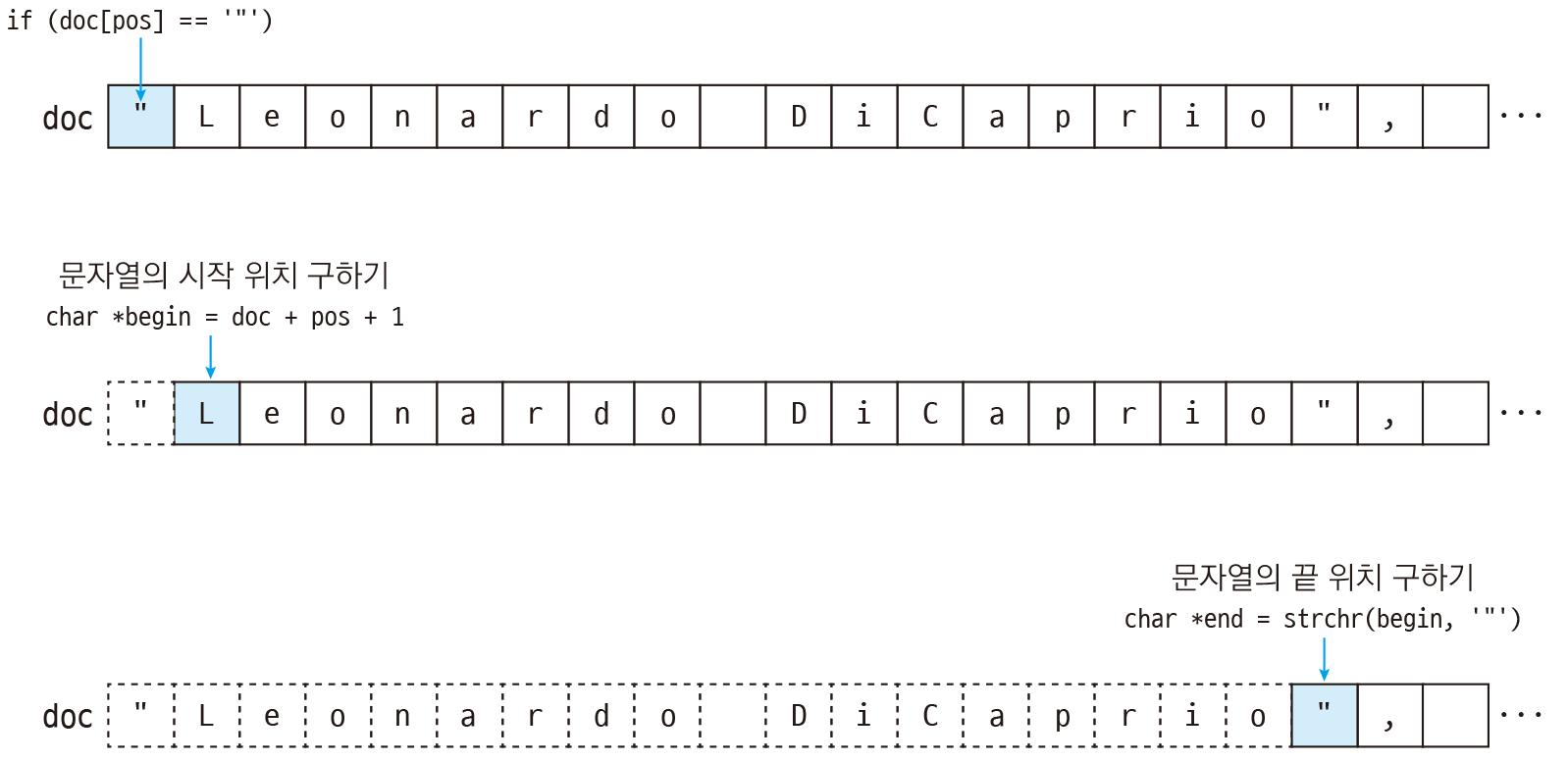
이제 "이 나오면 문자열입니다(여기서는 문자열 배열만 처리하겠습니다). 먼저 맨 앞의 "를 제외한 문자열의 시작 위치를 구합니다. 그리고 strchr 함수로 문자열의 끝 위치인 다음 "의 위치를 구합니다. 만약 "가 없으면 잘못된 문법이므로 반복을 종료합니다.
// 여기서는 문자열만 처리 if (doc[pos] == '"') // 문자가 "이면 문자열 { // 문자열의 시작 위치를 구함. 맨 앞의 "를 제외하기 위해 + 1 char *begin = doc + pos + 1; // 문자열의 끝 위치를 구함. 다음 "의 위치 char *end = strchr(begin, '"'); if (end == NULL) // "가 없으면 잘못된 문법이므로 break; // 반복을 종료 }
다음은 문자열 배열에서 문자열의 시작 위치 begin과 끝 위치 end를 구하는 과정입니다.
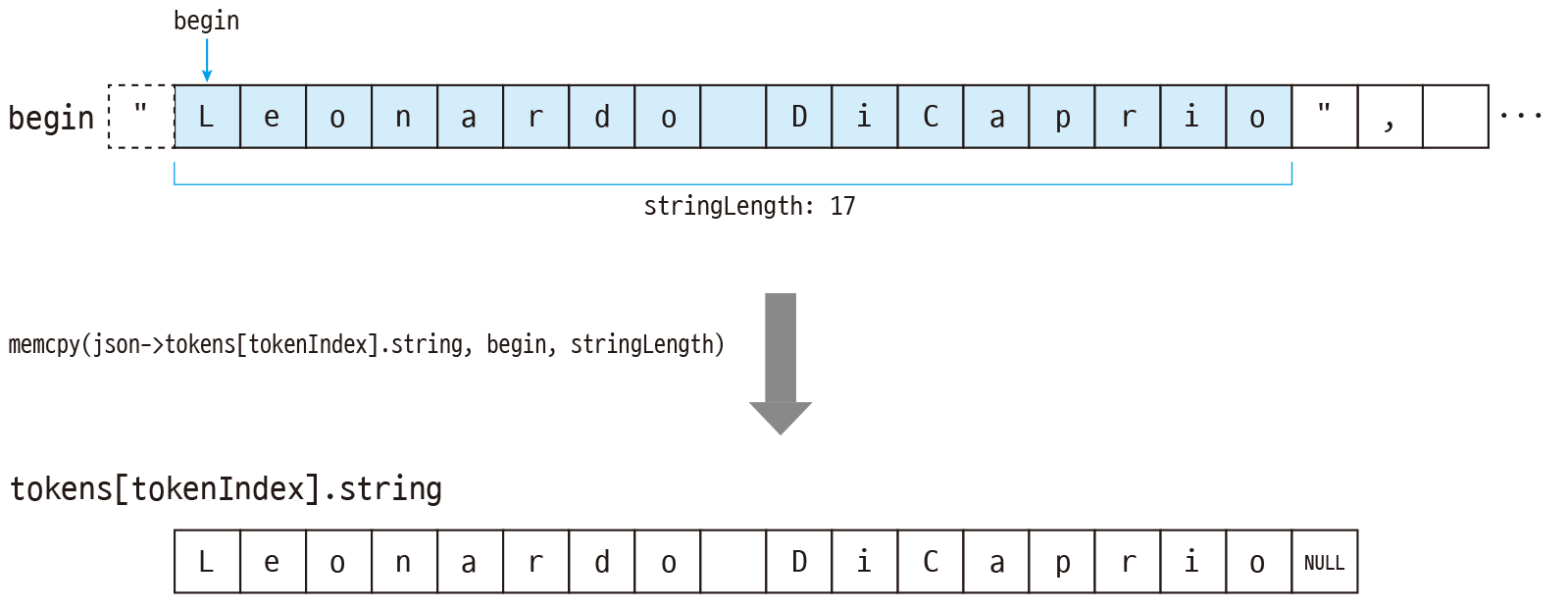
문자열의 실제 길이를 구한 뒤 토큰 배열의 요소에 문자열을 저장합니다. 토큰 종류에는 TOKEN_STRING을 지정하여 토큰이 문자열이라는 것을 표시해주고, 문자열 포인터에는 문자열 길이 + NULL 공간만큼 메모리를 할당하고 0으로 초기화합니다. 여기서 현재 문자열은 배열의 요소이므로 isArray에 true를 지정해줍니다.
int stringLength = end - begin; // 문자열의 실제 길이는 끝 위치 - 시작 위치 // 토큰 배열에 문자열 저장 // 토큰 종류는 문자열 json->tokens[tokenIndex].type = TOKEN_STRING; // 문자열 길이 + NULL 공간만큼 메모리 할당 json->tokens[tokenIndex].string = malloc(stringLength + 1); // 현재 문자열은 배열의 요소 json->tokens[tokenIndex].isArray = true; // 할당한 메모리를 0으로 초기화 memset(json->tokens[tokenIndex].string, 0, stringLength + 1);
이제 memcpy 함수로 문자열 시작 위치에서 문자열 길이만큼만 복사하여 문자열을 토큰에 저장합니다. 그리고 모든 처리가 끝나면 토큰 인덱스를 1 증가시키고, pos에는 문자열 길이와 "의 크기 1을 더해서 다음 문자열을 처리할 수 있도록 만듭니다.
// 문서에서 문자열을 토큰에 저장 // 문자열 시작 위치에서 문자열 길이만큼만 복사 memcpy(json->tokens[tokenIndex].string, begin, stringLength); tokenIndex++; // 토큰 인덱스 증가 pos = pos + stringLength + 1; // 현재 위치 + 문자열 길이 + "(+ 1) } pos++; // 다음 문자로 }
다음은 문자열 배열의 문자열을 토큰에 저장하는 과정입니다.
이제 main 함수에서 JSON 문서의 Actors에 저장한 문자열 배열도 함께 출력할 수 있게 수정합니다(전체 파일은 GitHub 저장소의 Unit 83/83.4/json/json 폴더에 들어있습니다).
json.c
int main() { int size; // 문서 크기 // 파일에서 JSON 문서를 읽음, 문서 크기를 구함 char *doc = readFile("example.json", &size); if (doc == NULL) return -1; JSON json = { 0, }; // JSON 구조체 변수 선언 및 초기화 parseJSON(doc, size, &json); // JSON 문서 파싱 printf("Title: %s\n", json.tokens[1].string); // 토큰에 저장된 문자열 출력(Title) printf("Genre: %s\n", json.tokens[3].string); // 토큰에 저장된 문자열 출력(Genre) printf("Director: %s\n", json.tokens[5].string); // 토큰에 저장된 문자열 출력(Director) printf("Actors:\n"); printf(" %s\n", json.tokens[7].string); // 토큰에 저장된 문자열 출력(Actors 배열의 요소) printf(" %s\n", json.tokens[8].string); // 토큰에 저장된 문자열 출력(Actors 배열의 요소) printf(" %s\n", json.tokens[9].string); // 토큰에 저장된 문자열 출력(Actors 배열의 요소) printf(" %s\n", json.tokens[10].string); // 토큰에 저장된 문자열 출력(Actors 배열의 요소) printf(" %s\n", json.tokens[11].string); // 토큰에 저장된 문자열 출력(Actors 배열의 요소) freeJSON(&json); // json 안에 할당된 동적 메모리 해제 free(doc); // 문서 동적 메모리 해제 return 0; }
Visual Studio에서 Ctrl+F5 키를 눌러서 프로그램을 실행하면 다음과 같이 JSON 문서의 Actors 배열도 함께 출력됩니다.
실행 결과
Title: Inception Genre: Sci-Fi Director: Christopher Nolan Actors: Leonardo DiCaprio Joseph Gordon-Levitt Ellen Page Tom Hardy Ken Watanabe
JSON 문서를 파싱했을 때 배열의 요소는 토큰에서 키(Actors) 문자열 뒤에 연달아서 위치합니다. 따라서 json.tokens에 인덱스를 7, 8, 9, 10, 11과 같이 지정하면 배열의 요소를 출력할 수 있습니다. 좀 더 편리하게 배열의 요소를 출력하는 방법은 뒤에서 설명하겠습니다.