46.3 웹 페이지의 HTML을 가져와서 파일로 저장하기
이제 기상청 웹 사이트에서 도시별 현재날씨 페이지의 HTML을 가져와보겠습니다. 웹 브라우저를 실행하고 다음 주소로 이동합니다.
- 도시별 현재날씨 > 지상관측자료 > 관측자료 > 날씨 > 기상청
http://www.kma.go.kr/weather/observation/currentweather.jsp
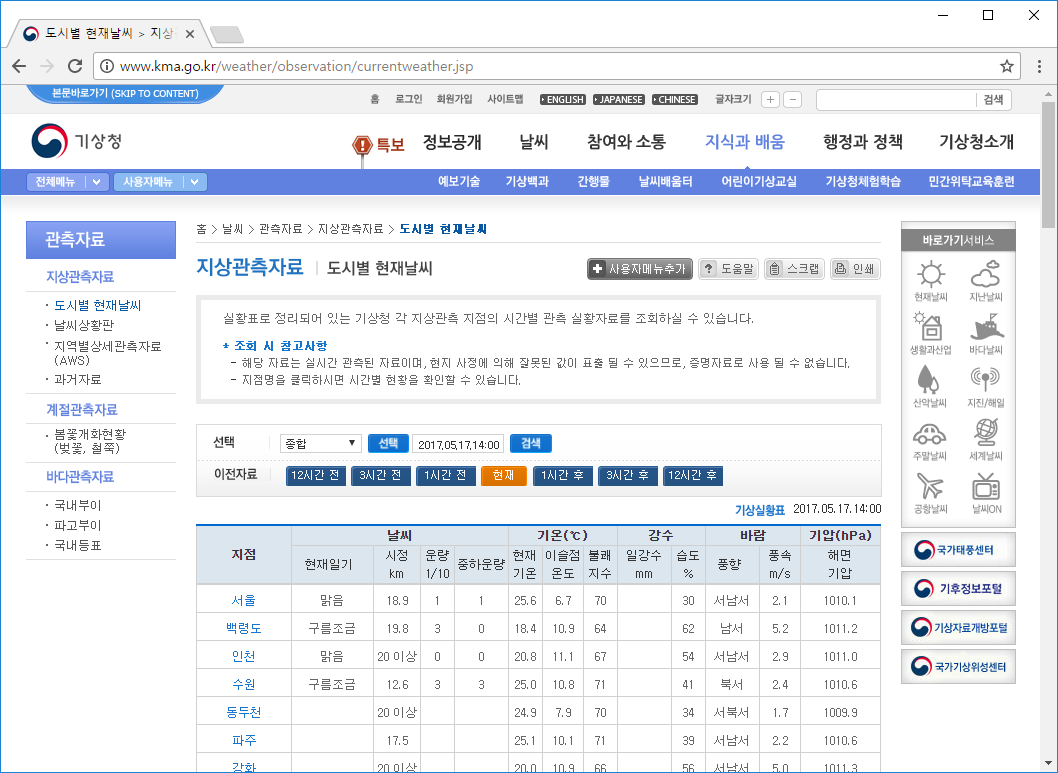
웹 페이지를 보면 도시별 기상 데이터가 나옵니다. 많은 데이터가 표시되지만 우리는 이 웹 페이지에서 지점, 기온(현재기온), 습도만 가져오겠습니다.
참고로 기상청 웹 사이트는 시간이 지나면 개편을 하므로 웹 페이지의 HTML 구조도 바뀌게 됩니다. 특히 파이썬 코딩 도장 책이 나온 뒤에 기상청 웹 사이트가 개편되었을 경우에는 책 내용대로 실습을 할 수 없게 됩니다. 따라서 이번 유닛에서는 원활한 실습을 위해 도시별 현재날씨 페이지를 복사해서 올려놓은 Bitbucket 주소를 사용하겠습니다.
46.3.1 가져올 HTML 확인하기
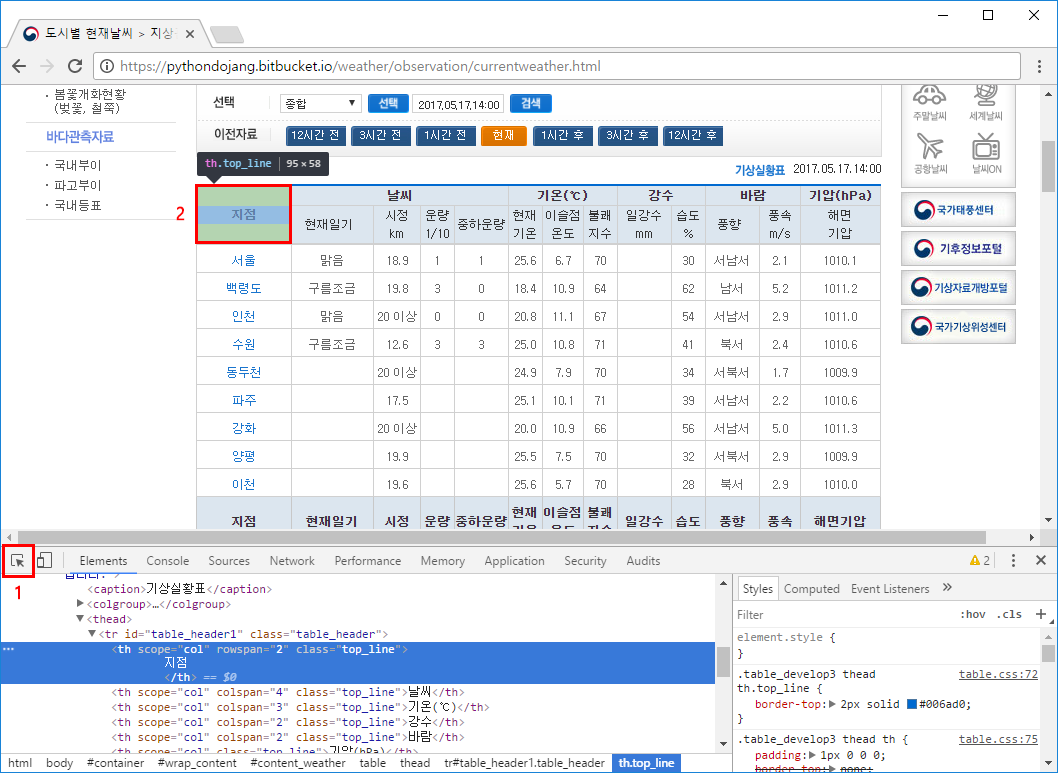
그럼 웹 브라우저에서 다음 주소로 이동하고, F12를 눌러서 개발자 도구를 표시합니다(여기서는 크롬을 사용하겠습니다). 그리고 왼쪽 아래 커서 버튼을 클릭(Ctrl+Shift+C)한 뒤 현재날씨 표에서 지점을 클릭합니다.
- Bitbucket 도시별 현재날씨 페이지
https://pythondojang.bitbucket.io/weather/observation/currentweather.html
참고 | 웹 페이지가
열리지 않는다면?
만약 위 웹 페이지가 열리지 않는다면 HTML을 가져오는 과정은 생략하고, GitHub 저장소의 Unit 46/weather.txt 파일을 이용하여 '46.4 데이터로 그래프 그리기' 실습을 진행하기 바랍니다.
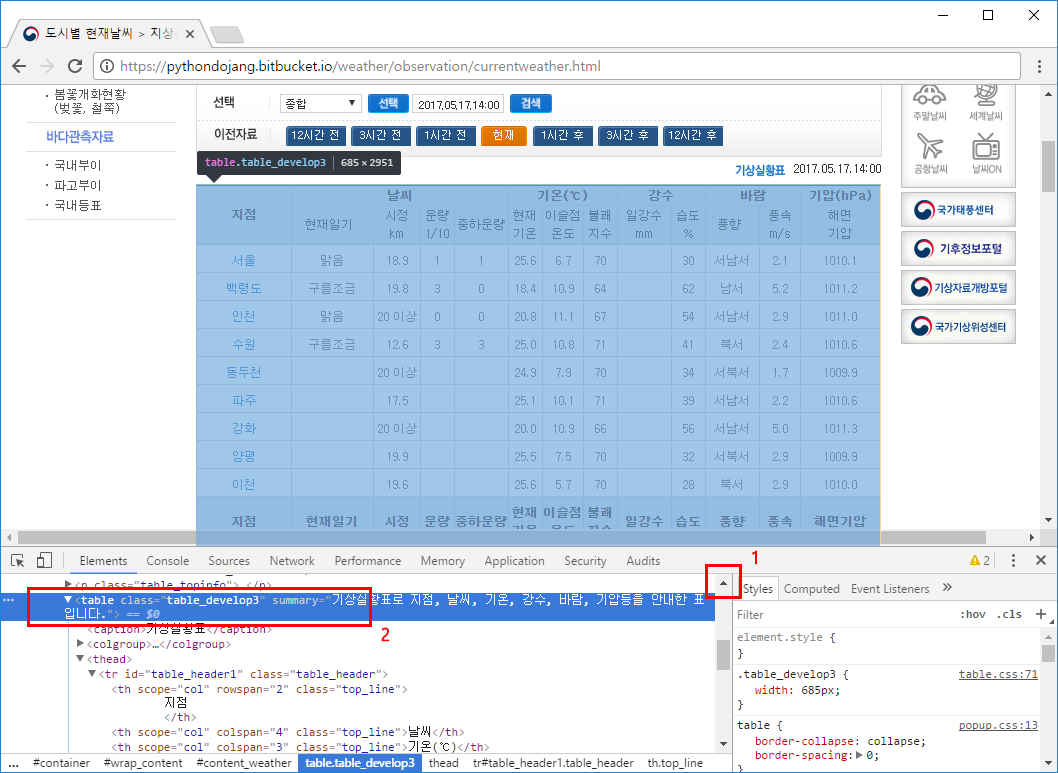
이제 지점에 해당하는 HTML 코드가 표시됩니다. 여기서 스크롤을 위쪽으로 조금 올린 뒤 <table class="table_develop3" 부분을 클릭합니다. 그러면 표 전체가 선택되는데 이 표가 우리가 가져올 부분입니다.
46.3.2 주피터 노트북 만들기
가져올 HTML을 확인했으면 주피터 노트북에 프로젝트 폴더(C:\project)를 지정해서 실행합니다(여기서는 반드시 아나콘다의 python.exe를 사용해야 합니다. 기존 파이썬 인터프리터를 사용하면 안 됩니다).
C:\Users\dojang>C:\Users\dojang\Anaconda3\python.exe -m notebook --notebook-dir C:\project
주피터 노트북에서 새 노트북을 만든 뒤 코드 셀에 다음 내용을 입력합니다.
weather.ipynb
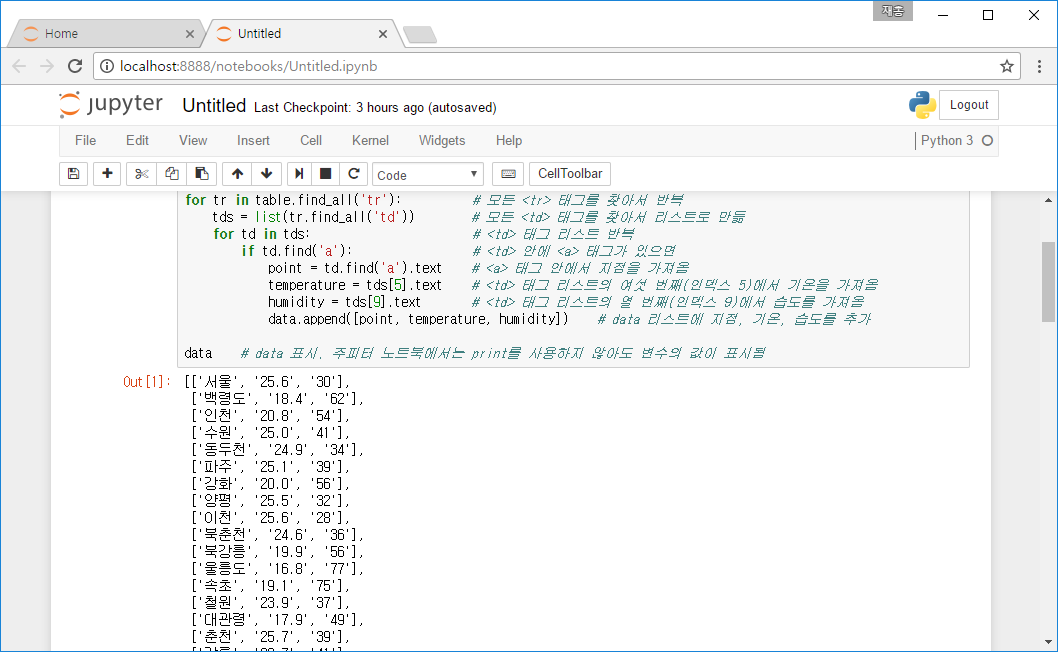
import requests # 웹 페이지의 HTML을 가져오는 모듈 from bs4 import BeautifulSoup # HTML을 파싱하는 모듈 # 웹 페이지를 가져온 뒤 BeautifulSoup 객체로 만듦 response = requests.get('https://pythondojang.bitbucket.io/weather/observation/currentweather.html') soup = BeautifulSoup(response.content, 'html.parser') table = soup.find('table', { 'class': 'table_develop3' }) # <table class="table_develop3">을 찾음 data = [] # 데이터를 저장할 리스트 생성 for tr in table.find_all('tr'): # 모든 <tr> 태그를 찾아서 반복(각 지점의 데이터를 가져옴) tds = list(tr.find_all('td')) # 모든 <td> 태그를 찾아서 리스트로 만듦 # (각 날씨 값을 리스트로 만듦) for td in tds: # <td> 태그 리스트 반복(각 날씨 값을 가져옴) if td.find('a'): # <td> 안에 <a> 태그가 있으면(지점인지 확인) point = td.find('a').text # <a> 태그 안에서 지점을 가져옴 temperature = tds[5].text # <td> 태그 리스트의 여섯 번째(인덱스 5)에서 기온을 가져옴 humidity = tds[9].text # <td> 태그 리스트의 열 번째(인덱스 9)에서 습도를 가져옴 data.append([point, temperature, humidity]) # data 리스트에 지점, 기온, 습도를 추가 data # data 표시. 주피터 노트북에서는 print를 사용하지 않아도 변수의 값이 표시됨
실행을 해보면 Out [1]: 부분에 data의 값이 표시됩니다. 여기서 Out [1]:은 In [1]:의 출력이라는 뜻입니다.
46.3.3 HTML의 데이터를 가져오는 방식 알아보기
그럼 지점, 기온(현재기온), 습도 값을 어떻게 가져오는지 알아보겠습니다. 웹 브라우저의 개발자 모드에서 왼쪽 아래 커서 버튼을 클릭(Ctrl+Shift+C)한 뒤 서울을 클릭합니다. 그러면 서울에 해당하는 태그들이 출력됩니다. 그다음에 서울의 현재기온 25.6과 습도 30도 클릭해봅니다. 이런 방식으로 HTML 코드와 웹 페이지 화면을 보면서 어떤 태그가 원하는 값인지 찾습니다.
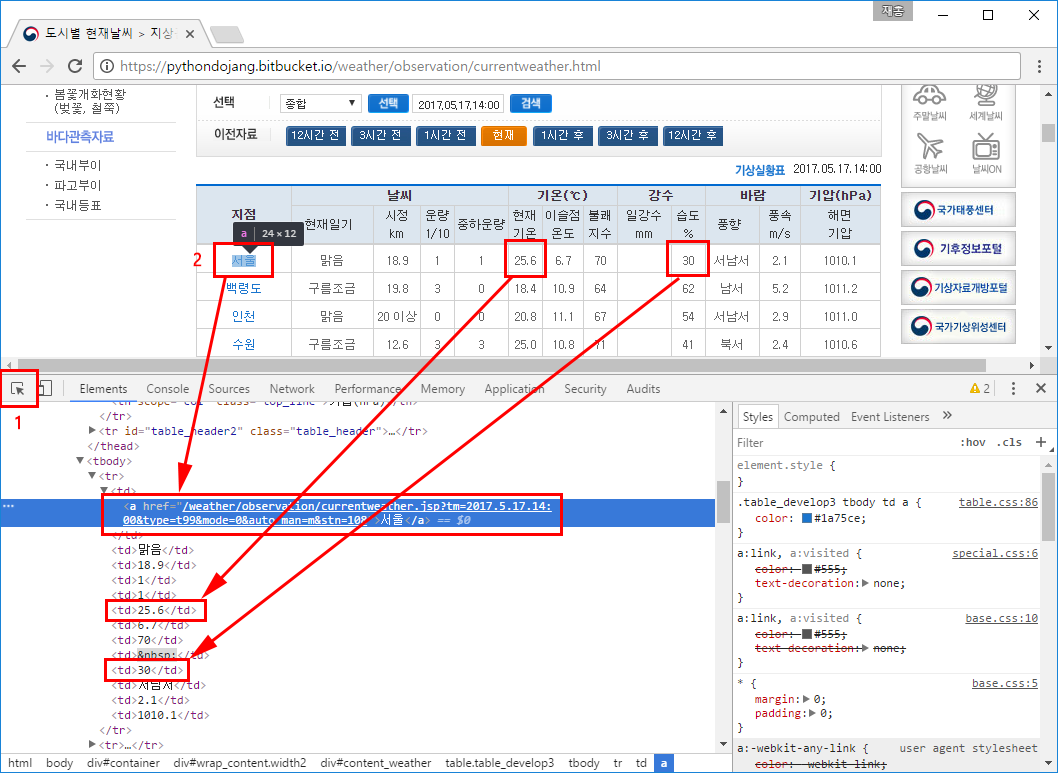
이제 HTML 코드를 살펴보겠습니다. <table>에서 도시(지점)별 데이터는 <tr> 태그로 묶여 있고, 세부 값은 <td> 태그에 들어있습니다. 여기서는 <td> 태그 안에 <a> 태그가 있으면 지점이라 판단하고, 지점 값을 가져옵니다. 그다음에 기온은 여섯 번째(인덱스 5) <td>의 값을 가져오고, 습도는 열 번째(인덱스 9) <td>의 값을 가져오면 됩니다.
<table class="table_develop3" summary="기상실황표로 지점, 날씨, 기온, 강수, 바람, 기압등을 안내한 표입니다."> ...생략... <tr> <td><a href="/weather/observation/currentweather.jsp?tm=2017.5.17.14:00&type=t99&mode=0&auto_man=m&stn=108" >서울</a></td> <td>맑음</td> <td>18.9</td> <td>1</td> <td>1</td> <td>25.6</td> <td>6.7</td> <td>70</td> <td> </td> <td>30</td> <td>서남서</td> <td>2.1</td> <td>1010.1</td> </tr> ...생략...
다시 파이썬에서 HTML을 가져오는 부분입니다. 여기서는 requests 모듈로 웹 페이지의 HTML을 가져오고, bs4 모듈로 HTML을 파싱합니다(HTML 파싱은 텍스트 형태의 HTML 코드를 분석해서 객체로 만든 뒤 검색하거나 편집할 수 있도록 만드는 작업입니다. 그리고 bs4는 BeautifulSoup 라이브러리이고 HTML 코드를 파싱하는데 사용합니다).
import requests # 웹 페이지의 HTML을 가져오는 모듈 from bs4 import BeautifulSoup # HTML을 파싱하는 모듈 # 웹 페이지를 가져온 뒤 BeautifulSoup 객체로 만듦 response = requests.get('https://pythondojang.bitbucket.io/weather/observation/currentweather.html') soup = BeautifulSoup(response.content, 'html.parser')
request.get에 URL을 넣으면 응답(Response) 객체가 나옵니다. 그리고 BeautifulSoup 클래스에 응답 객체의 content 속성과 'html.parser'를 넣습니다. content 속성에는 텍스트 형태의 HTML이 들어있으며, 파이썬의 html.parser 모듈을 사용해서 파싱하도록 설정합니다.
참고 | 아나콘다를
사용하지 않는다면?
requests와 bs4는 기본적으로 파이썬에 포함되어 있지 않습니다. 따라서 pip install requests, pip install bs4로 패키지를 설치해줍니다.
이제 BeautifulSoup 클래스로 만든 soup 객체로 태그를 찾습니다. 먼저 soup.find('table', { 'class': 'table_develop3' })과 같이 HTML의 class 속성(attribute)이 table_develop3인 <table> 태그를 찾습니다(HTML의 class는 태그의 스타일을 지정할 때 사용하는 속성이며 파이썬의 클래스와는 다릅니다).
table = soup.find('table', { 'class': 'table_develop3' }) # <table class="table_develop3">을 찾음
그다음에는 데이터를 저장할 리스트 data를 만듭니다. 그리고 for tr in table.find_all('tr'):과 같이 table에서 모든 <tr> 태그를 찾아서 반복합니다. 즉, 이 <tr> 태그에 서울, 백령도, 인천 등 지점별 데이터가 들어있으므로 반복할 때마다 서울, 백령도, 인천 등 각 지점의 데이터를 가져옵니다.
data = [] # 데이터를 저장할 리스트 생성 for tr in table.find_all('tr'): # 모든 <tr> 태그를 찾아서 반복(각 지점의 데이터를 가져옴)
각 지점의 데이터를 가져왔으면 list(tr.find_all('td'))과 같이 tr에서 모든 <td> 태그를 찾아서 리스트로 만듭니다. 이렇게 하면 지점, 현재일기, 시정, 운량, 중하운량, 현재기온, 이슬점온도, 불쾌지수, 일강수, 습도, 풍향, 풍속, 해면기압 <td>가 리스트에 들어갑니다.
tds = list(tr.find_all('td')) # 모든 <td> 태그를 찾아서 리스트로 만듦 # (각 날씨 값을 리스트로 만듦)
이제 <td> 태그 리스트 tds를 반복하면서 각 값을 가져옵니다. 먼저 if td.find('a'):와 같이 td에 <a> 태그가 있는지 확인합니다. <a> 태그가 있으면 td.find('a').text와 같이 <a> 태그의 text속성에서 지점을 가져옵니다(text 속성은 <태그>텍스트</태그>에서 태그 안에 들어있는 텍스트를 가져옵니다). 그리고 기온(현재기온)은 여섯 번째(인덱스 5), 습도는 열 번째(인덱스 9)에 있다는 것을 확인했으므로 tds[5].text에서 기온을 가져오고, tds[9].text에서 습도를 가져옵니다.
for td in tds: # <td> 태그 리스트 반복(각 날씨 값을 가져옴) if td.find('a'): # <td> 안에 <a> 태그가 있으면(지점인지 확인) point = td.find('a').text # <a> 태그 안에서 지점을 가져옴 temperature = tds[5].text # <td> 태그 리스트의 여섯 번째(인덱스 5)에서 기온을 가져옴 humidity = tds[9].text # <td> 태그 리스트의 열 번째(인덱스 9)에서 습도를 가져옴 data.append([point, temperature, humidity]) # data 리스트에 지점, 기온, 습도를 추가
필요한 값을 가져왔으면 data 리스트 안에 [point, temperature, humidity]처럼 값을 리스트 형태로 추가해줍니다.
data.append([point, temperature, humidity]) # data 리스트에 지점, 기온, 습도를 추가
참고 | 웹 페이지
크롤링
지금까지 작성한 웹 페이지 크롤링 코드는 특정 태그가 있는지, 몇 번째에 위치한 태그를 가져온다든지 해서 생각보다 체계적이지 못한 느낌이 듭니다. 왜냐하면 우리가 가져오는 웹 페이지는 데이터를 화면에 보여주는게 목적일 뿐 데이터를 체계적으로 저장하는데는 적합하지 않기 때문입니다. 그래서 주어진 HTML 구성에 맞춰서 만들다 보니 코드가 깔끔하지 않습니다. 즉, 크롤링은 웹 페이지마다 전부 코드가 다르게 나오며 같은 웹 페이지라도 개편이 되면 크롤링 코드를 다시 만들어야 합니다.
46.3.4 데이터를 csv 파일에 저장하기
데이터가 완성되었으니 이 데이터를 파일에 저장해보겠습니다. 방금 data의 값을 출력한 뒤에 코드 셀이 하나 더 생겼을 겁니다. 이 코드 셀에서 다음 코드를 실행합니다(셸이 생기지 않았다면 메뉴의 Insert > Insert Cell Below 실행).
weather.ipynb
with open('weather.csv', 'w') as file: # weather.csv 파일을 쓰기 모드로 열기 file.write('point,temperature,humidity\n') # 컬럼 이름 추가 for i in data: # data를 반복하면서 file.write('{0},{1},{2}\n'.format(i[0], i[1], i[2])) # 지점,온도,습도를 줄 단위로 저장
코드를 실행하면 프로젝트 폴더(C:\project)에 weather.csv 파일이 생성됩니다. csv 파일은 Comma-separated values의 약자인데 각 컬럼을 ,(콤마)로 구분해서 표현한다고 해서 csv라고 부릅니다. 여기서는 file.write('point,temperature,humidity\n')처럼 맨 윗줄에 컬럼 이름을 추가하고 그 다음 줄부터는 data를 반복하면서 file.write('{0},{1},{2}\n'.format(i[0], i[1], i[2]))와 같이 지점, 온도, 습도를 줄단위로 저장합니다. 이때 콤마와 값 사이에는 공백을 넣지 않고 반드시 붙여줍니다.
weather.csv 파일을 메모장이나 기타 텍스트 편집기로 열어보면 다음과 같은 모양으로 지점, 기온, 습도 값이 저장된 것을 볼 수 있습니다.
weather.csv
point,temperature,humidity 서울,25.6,30 백령도,18.4,62 인천,20.8,54 수원,25.0,41 ...생략...
특히 csv 파일을 저장할 때 컬럼 이름은 영어로 지정해줍니다. 영어로 지정하면 나중에 각 컬럼에 접근할 때 df.temperature처럼 속성으로 깔끔하게 사용할 수 있습니다.