74.1 연결 리스트 구조체 만들고 사용하기
먼저 연결 리스트의 구조체를 정의합니다. 연결 리스트는 노드들의 집합이므로 실제로는 노드의 구조체만 정의하면 됩니다.
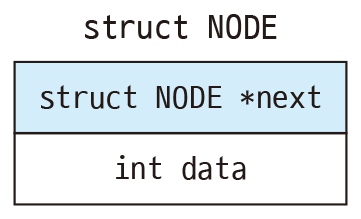
struct NODE { // 연결 리스트의 노드 구조체 struct NODE *next; // 다음 노드의 주소를 저장할 포인터 int data; // 데이터를 저장할 멤버 };
NODE 구조체에서 가장 중요한 부분은 struct NODE *next;입니다. 얼핏 보면 구조체 자기 자신의 포인터를 멤버로 가지고 있는데 전혀 어렵지 않습니다. next에는 NODE 구조체로 만든 다른 노드의 메모리 주소를 저장합니다. 즉, 자기 자신이 아닌 다른 노드의 메모리 주소를 저장한다는 점을 기억하세요.
NODE 구조체에서 데이터는 int형 하나만 저장했습니다. 실제로 사용할 때는 용도에 따라서 다양한 자료형으로 된 멤버 여러 개를 넣으면 됩니다.
이제 단일 연결 리스트에서 노드의 종류를 알아보겠습니다. 노드는 역할에 따라서 두 가지로 나뉩니다.
- 머리 노드(head node): 단일 연결 리스트의 기준점이며 헤드(head)라고도 부릅니다. 머리 노드는 첫 번째 노드를 가리키는 용도이므로 데이터를 저장하지 않습니다.
- 노드(node): 단일 연결 리스트에서 데이터가 저장되는 실제 노드입니다.
이 두 종류의 노드는 역할만 다를 뿐 모두 NODE 구조체를 사용합니다.
이제 NODE 구조체로 머리 노드를 만든 뒤 노드가 2개인 연결 리스트를 만들어보겠습니다. 그림으로 표현하면 다음과 같이 head → node1 → node2 → NULL과 같은 모양입니다.

다음 내용을 소스 코드 편집 창에 입력한 뒤 실행해보세요.
linked_list_two_nodes.c
#include <stdio.h> #include <stdlib.h> // malloc, free 함수가 선언된 헤더 파일 struct NODE { // 연결 리스트의 노드 구조체 struct NODE *next; // 다음 노드의 주소를 저장할 포인터 int data; // 데이터를 저장할 멤버 }; int main() { struct NODE *head = malloc(sizeof(struct NODE)); // 머리 노드 생성 // 머리 노드는 데이터를 저장하지 않음 struct NODE *node1 = malloc(sizeof(struct NODE)); // 첫 번째 노드 생성 head->next = node1; // 머리 노드 다음은 첫 번째 노드 node1->data = 10; // 첫 번째 노드에 10 저장 struct NODE *node2 = malloc(sizeof(struct NODE)); // 두 번째 노드 생성 node1->next = node2; // 첫 번째 노드 다음은 두 번째 노드 node2->data = 20; // 두 번째 노드에 20 저장 node2->next = NULL; // 두 번째 노드 다음은 노드가 없음(NULL) struct NODE *curr = head->next; // 연결 리스트 순회용 포인터에 첫 번째 노드의 주소 저장 while (curr != NULL) // 포인터가 NULL이 아닐 때 계속 반복 { printf("%d\n", curr->data); // 현재 노드의 데이터 출력 curr = curr->next; // 포인터에 다음 노드의 주소 저장 } free(node2); // 노드 메모리 해제 free(node1); // 노드 메모리 해제 free(head); // 머리 노드 메모리 해제 return 0; }
실행 결과
10 20
연결 리스트에서 노드를 추가하는 규칙은 간단합니다.
- 노드에 메모리 할당
- next 멤버에 다음 노드의 메모리 주소 저장
- data 멤버에 데이터 저장
- 마지막 노드라면 next 멤버에 NULL 저장
먼저 머리 노드를 생성합니다. 머리 노드는 연결 리스트의 기준점 역할만 하므로 데이터는 저장하지 않습니다.
struct NODE *head = malloc(sizeof(struct NODE)); // 머리 노드 생성 // 머리 노드는 데이터를 저장하지 않음
이제 첫 번째 노드를 생성한 뒤 머리 노드의 next에 첫 번째 노드의 주소를 저장합니다. 다시 두 번째 노드를 생성한 뒤 첫 번째 노드의 next에 두 번째 노드의 주소를 저장합니다. 마지막으로 두 번째 노드의 다음에는 노드가 없으므로 NULL을 저장하면 됩니다.
struct NODE *node1 = malloc(sizeof(struct NODE)); // 첫 번째 노드 생성 head->next = node1; // 머리 노드 다음은 첫 번째 노드 node1->data = 10; // 첫 번째 노드에 10 저장 struct NODE *node2 = malloc(sizeof(struct NODE)); // 두 번째 노드 생성 node1->next = node2; // 첫 번째 노드 다음은 두 번째 노드 node2->data = 20; // 두 번째 노드에 20 저장 node2->next = NULL; // 두 번째 노드 다음은 노드가 없음(NULL)
이렇게 생성한 연결 리스트를 그림으로 표현하면 다음과 같은 모양이 됩니다.

이제 연결 리스트의 모든 노드를 순회하는 방법입니다. 간단하게 연결 리스트에서 마지막 노드의 다음(next)은 NULL이라는 점을 이용합니다. 먼저 연결 리스트 순회용 포인터 curr를 새로 생성해서 첫 번째 노드의 주소(head->next)를 저장합니다(절대 연결 리스트 자체를 건드리면 안 됩니다). 그리고 curr가 NULL이 아닐 때 계속 반복합니다. 반복문 안에서는 현재 노드의 데이터를 출력하고 curr에 curr->next를 저장하면 됩니다. 그럼 next를 계속 따라가다가 마지막에 다다르면 NULL이 나오니까 반복이 끝나겠죠?
struct NODE *curr = head->next; // 연결 리스트 순회용 포인터에 첫 번째 노드의 주소 저장 while (curr != NULL) // 포인터가 NULL이 아닐 때 계속 반복 { printf("%d\n", curr->data); // 현재 노드의 데이터 출력 curr = curr->next; // 포인터에 다음 노드의 주소 저장 }
연결 리스트 사용이 끝났다면 free 함수로 일반 노드와 머리 노드의 메모리를 해제합니다.
free(node2); // 노드 메모리 해제 free(node1); // 노드 메모리 해제 free(head); // 머리 노드 메모리 해제