28.2 N-gram 만들기
N-gram은 문자열에서 N개의 연속된 요소를 추출하는 방법입니다. 만약 'Hello'라는 문자열을 문자(글자) 단위 2-gram으로 추출하면 다음과 같이 됩니다.
He el ll lo
즉, 문자열의 처음부터 문자열 끝까지 한 글자씩 이동하면서 2글자를 추출합니다. 3-gram은 3글자, 4-gram은 4글자를 추출하겠죠?
28.2.1 반복문으로 N-gram 출력하기
이제 반복문으로 문자 단위 2-gram을 출력해보겠습니다.
2_gram_character.py
text = 'Hello' for i in range(len(text) - 1): # 2-gram이므로 문자열의 끝에서 한 글자 앞까지만 반복함 print(text[i], text[i + 1], sep='') # 현재 문자와 그다음 문자 출력
실행 결과
He el ll lo
생각보다 간단하죠? 2-gram이므로 문자열의 끝에서 한 글자 앞까지만 반복하면서 현재 문자와 그다음 문자 두 글자씩 출력합니다.
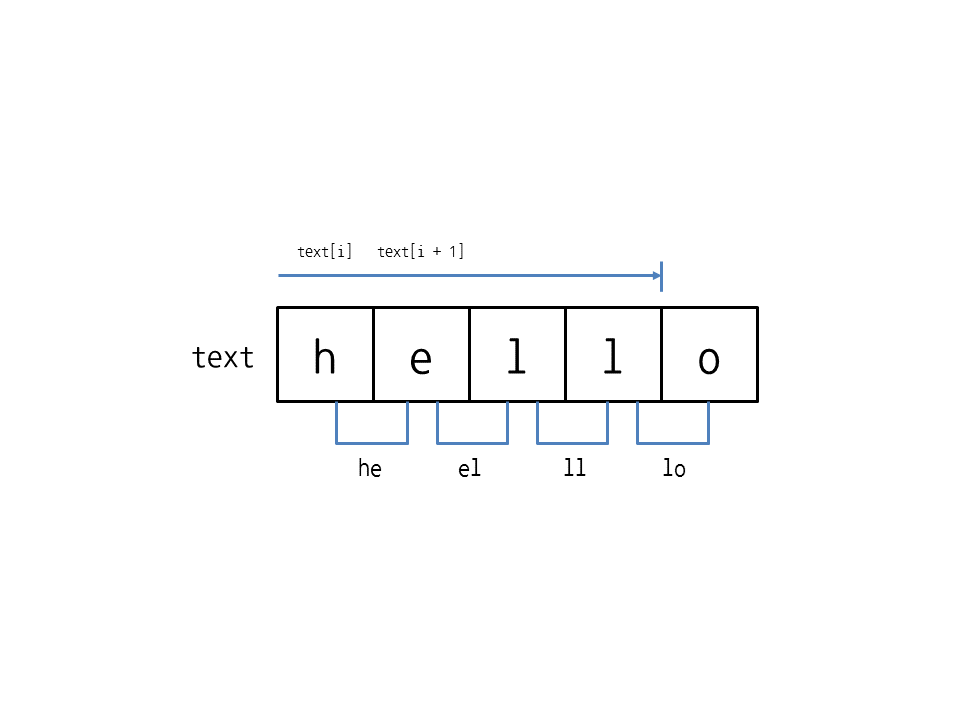
만약 3-gram이라면 반복 횟수는 range(len(text) - 2))와 같이 되고, 문자열 끝에서 두 글자 앞까지 반복하면 됩니다. 문자열을 출력할 때는 print(text[i], text[i + 1], text[i + 2], sep='')가 되겠죠? 여기서 문자열의 끝까지 반복하면 text[i + 1], text[i + 2]는 문자열의 범위를 벗어난 접근을 하게 되므로 주의해야 합니다.
글자 단위 N-gram이 있다면 단어 단위 N-gram도 있겠죠? 다음은 문자열을 공백으로 구분하여 단어 단위 2-gram을 출력합니다. 예를 들어 'this is python script'는 'this is', 'is python', 'python script'가 됩니다.
2_gram_word.py
text = 'this is python script' words = text.split() # 공백을 기준으로 문자열을 분리하여 리스트로 만듦 for i in range(len(words) - 1): # 2-gram이므로 리스트의 마지막에서 요소 한 개 앞까지만 반복함 print(words[i], words[i + 1]) # 현재 문자열과 그다음 문자열 출력
실행 결과
this is is python python script
단어 단위 2-gram도 간단합니다. split을 사용하여 공백을 기준으로 문자열을 분리하여 리스트로 만듭니다. 그리고 2-gram이므로 words 리스트의 마지막에서 요소 한 개 앞까지만 반복하면서 현재 문자열과 그다음 문자열을 출력하면 됩니다.
28.2.2 zip으로 2-gram 만들기
이번에는 zip 함수로 2-gram을 만드는 방법을 알아보겠습니다.
2_gram_character_zip.py
text = 'hello' two_gram = zip(text, text[1:]) for i in two_gram: print(i[0], i[1], sep='')
실행 결과
He el ll lo
지금까지 zip 함수는 리스트 두 개를 딕셔너리로 만들 때 사용했는데, zip 함수는 반복 가능한 객체의 각 요소를 튜플로 묶어줍니다.
zip(text, text[1:])은 문자열 text와 text[1:]의 각 요소를 묶어서 튜플로 만듭니다. text[1:]은 인덱스 1(두 번째 문자)부터 마지막 문자까지 가져오죠? 따라서 text와 text[1:]을 zip으로 묶으면 문자 하나가 밀린 상태로 각 문자를 묶게 됩니다.
>>> text = 'hello' >>> list(zip(text, text[1:])) [('h', 'e'), ('e', 'l'), ('l', 'l'), ('l', 'o')]
2-gram 리스트가 만들어졌죠? 이 리스트를 출력할 때는 for i in two_gram:와 같이 for로 반복하면서 print(i[0], i[1], sep='')로 튜플의 요소를 출력해주면 됩니다.
단어 단위 2-gram도 같은 방법으로 만들면 됩니다. 문자열을 공백으로 분리하여 리스트로 만드는 것 말고는 앞과 같습니다.
>>> text = 'this is python script' >>> words = text.split() >>> list(zip(words, words[1:])) [('this', 'is'), ('is', 'python'), ('python', 'script')]
만약 3-gram을 만들고 싶다면 zip(words, words[1:], words[2:])와 같이 word, word[1:], word[2:] 3개의 리스트를 넣으면 되겠죠?
28.2.3 zip과 리스트 표현식으로 N-gram 만들기
N-gram을 만들 때 zip에 일일이 [1:], [2:]같은 슬라이스를 넣자니 상당히 번거롭습니다. 만약 N-gram의 숫자가 늘어나면 그만큼 슬라이스도 여러 개 입력해줘야 합니다. 그러면 이 과정을 코드로 만들 수는 없을까요? 다음과 같이 리스트 표현식을 사용하면 됩니다.
>>> text = 'hello' >>> [text[i:] for i in range(3)] ['hello', 'ello', 'llo']
[text[i:] for i in range(3)]처럼 for로 3번 반복하면서 text[i:]로 리스트를 생성했습니다. 여기서 for i in range(3)는 0, 1, 2까지 반복하므로 text[i:]는 text[0:], text[1:], text[2:]가 되죠? 즉, 3-gram에 필요한 슬라이스입니다. text[0:]은 text와 같으므로 지금까지 zip에 넣었던 모양입니다.
이제 리스트 ['hello', 'ello', 'llo']를 zip에 넣어보겠습니다.
>>> list(zip(['hello', 'ello', 'llo'])) [('hello',), ('ello',), ('llo',)]
결과를 보면 원하는 3-gram이 아닙니다. 왜 그럴까요? zip은 반복 가능한 객체 여러 개를 콤마로 구분해서 넣어줘야 합니다. 하지만 ['hello', 'ello', 'llo']은 요소가 3개 들어있는 리스트 1개이기 때문입니다.
zip에 리스트의 각 요소를 콤마로 구분해서 넣어주려면 리스트 앞에 *를 붙여야 합니다.
>>> list(zip(*['hello', 'ello', 'llo'])) [('h', 'e', 'l'), ('e', 'l', 'l'), ('l', 'l', 'o')]
이제 3-gram 리스트가 만들어졌습니다. 물론 리스트 표현식을 바로 zip에 넣어주려면 리스트 표현식 앞에 *를 붙이면 됩니다.
>>> list(zip(*[text[i:] for i in range(3)])) [('h', 'e', 'l'), ('e', 'l', 'l'), ('l', 'l', 'o')]
리스트에 *를 붙이는 방법은 리스트 언패킹(list unpacking)이라고 하는데 이 부분은 '30.1 위치 인수와 리스트 언패킹 사용하기'에서 자세히 설명하겠습니다.
지금까지 회문 판별과 N-gram을 만들어보았습니다. 여기서는 인덱스로 문자열을 다루는 방법과 reversed, zip을 활용하는 방법을 눈여겨 보는 것이 좋습니다. 그리고 reversed, zip으로 문제를 쉽게 해결할 수 있다고 해도 인덱스를 사용하는 방법은 꼭 익혀두기 바랍니다. 문제가 조금 변형되거나 예외가 생길 때는 인덱스를 활용해야 하는 경우도 있기 때문입니다.
읽을거리 | N-gram의 활용
4-gram을 쓰면 picked, picks, picking에서 pick만 추출하여 단어의 빈도를 세는데 이용됩니다. 이런 특성 때문에 검색엔진, 빅데이터, 법언어학 분야에서 주로 활용됩니다.
해리포터의 작가 조앤 롤링은 가명으로 <더 쿠쿠스 콜링>이라는 소설을 출간한 적이 있었습니다. 재미있는 점은 <더 쿠쿠스 콜링>의 작가가 조앤 롤링이라는 것을 밝혀내는데 N-gram을 비롯하여 다양한 기법이 동원되었습니다. 즉, 사람마다 사용하는 문장에 패턴이 있지요. 그래서 같은 의미라 하더라도 사람마다 단어 선택이 다르다는 것을 통계적으로 분석해낸 사례입니다.
조앤 롤링을 고백하게 만든 기술, 법언어학: http://yoonjiman.net/2013/07/23/how-forensic-linguistics-outed-j-k-rowling/