24.1 문자열 조작하기
Unit 24. 문자열 응용하기
지금까지 리스트 사용 방법을 알아보았습니다. 리스트는 요소 여러 개가 연속적으로 이어져 있죠? 마찬가지로 문자열도 문자 여러 개가 연속적으로 이어져 있는 시퀀스 자료형이라 리스트와 비슷한 점이 많습니다.
이번에는 문자열 메서드 사용 방법과 문자열 포매팅에 대해 알아보겠습니다.
24.1 문자열 조작하기
문자열은 문자열을 조작하거나 정보를 얻는 다양한 메서드(method)를 제공합니다(메서드는 '?34.1 클래스와 메서드 만들기'에서 설명하겠습니다). 파이썬에서 제공하는 문자열 메서드는 여러 가지가 있지만 여기서는 자주 쓰는 메서드를 다루겠습니다.
24.1.1 문자열 바꾸기
replace('바꿀문자열', '새문자열')은 문자열 안의 문자열을 다른 문자열로 바꿉니다(문자열 자체는 변경하지 않으며 바뀐 결과를 반환합니다). 다음은 문자열 'Hello, world!'에서 'world'를 'Python'으로 바꾼 뒤 결과를 반환합니다.
>>> 'Hello, world!'.replace('world', 'Python') 'Hello, Python!'
만약 바뀐 결과를 유지하고 싶다면 문자열이 저장된 변수에 replace를 사용한 뒤 다시 변수에 할당해주면 됩니다.
>>> s = 'Hello, world!' >>> s = s.replace('world!', 'Python') >>> s 'Hello, Python'
24.1.2 문자 바꾸기
replace는 문자열을 바꿨는데 문자를 바꾸는 방법도 있겠죠?
translate는 문자열 안의 문자를 다른 문자로 바꿉니다. 먼저 str.maketrans('바꿀문자', '새문자')로 변환 테이블을 만듭니다. 그다음에 translate(테이블)을 사용하면 문자를 바꾼 뒤 결과를 반환합니다. 다음은 문자열 'apple'에서 a를 1, e를 2, i를 3, o를 4, u를 5로 바꿉니다.
>>> table = str.maketrans('aeiou', '12345') >>> 'apple'.translate(table) '1ppl2'
24.1.3 문자열 분리하기
이제 문자열을 분리하는 방법입니다.
split()은 공백을 기준으로 문자열을 분리하여 리스트로 만듭니다. 지금까지 input으로 문자열을 입력받은 뒤 리스트로 만든 메서드가 바로 이 split입니다.
>>> 'apple pear grape pineapple orange'.split() ['apple', 'pear', 'grape', 'pineapple', 'orange']
split('기준문자열')과 같이 기준 문자열을 지정하면 기준 문자열로 문자열을 분리합니다. 즉, 문자열에서 각 단어가 ,(콤마)와 공백으로 구분되어 있을 때 ', '으로 문자열을 분리하면 단어만 리스트로 만듭니다.
>>> 'apple, pear, grape, pineapple, orange'.split(', ') ['apple', 'pear', 'grape', 'pineapple', 'orange']
24.1.4 구분자 문자열과 문자열 리스트 연결하기
문자열을 분리하여 리스트로 만들었으니 다시 연결하는 방법도 있겠죠?
join(리스트)는 구분자 문자열과 문자열 리스트의 요소를 연결하여 문자열로 만듭니다. 다음은 공백 ' '에 join을 사용하여 각 문자열 사이에 공백이 들어가도록 만듭니다..
>>> ' '.join(['apple', 'pear', 'grape', 'pineapple', 'orange']) 'apple pear grape pineapple orange'
마이너스 '-'에 join을 사용하면 각 문자열 사이에 마이너스가 들어가겠죠?
>>> '-'.join(['apple', 'pear', 'grape', 'pineapple', 'orange']) 'apple-pear-grape-pineapple-orange'
24.1.5 소문자를 대문자로 바꾸기
이번에는 문자열의 문자를 대소문자로 바꾸는 방법입니다.
upper()는 문자열의 문자를 모두 대문자로 바꿉니다. 만약 문자열 안에 대문자가 있다면 그대로 유지됩니다.
>>> 'python'.upper() 'PYTHON'
24.1.6 대문자를 소문자로 바꾸기
lower()는 문자열의 문자를 모두 소문자로 바꿉니다. 만약 문자열 안에 소문자가 있다면 그대로 유지됩니다.
>>> 'PYTHON'.lower() 'python'
24.1.7 왼쪽 공백 삭제하기
문자열을 사용하다 보면 공백을 삭제해야 할 경우가 생깁니다. 이때는 lstrip, rstrip, strip 메서드를 사용합니다.
lstrip()은 문자열에서 왼쪽에 있는 연속된 모든 공백을 삭제합니다(l은 왼쪽(left)을 의미).
>>> ' Python '.lstrip() 'Python '
24.1.8 오른쪽 공백 삭제하기
rstrip()은 문자열에서 오른쪽에 있는 연속된 모든 공백을 삭제합니다(r은 오른쪽(right)을 의미).
>>> ' Python '.rstrip() ' Python'
24.1.9 양쪽 공백 삭제하기
strip()은 문자열에서 양쪽에 있는 연속된 모든 공백을 삭제합니다.
>>> ' Python '.strip() 'Python'
24.1.10 왼쪽의 특정 문자 삭제하기
지금까지 lstrip, rstrip, strip으로 공백을 삭제했죠? 이번에는 문자열에서 특정 문자를 삭제해보겠습니다.
lstrip('삭제할문자들')과 같이 삭제할 문자들을 문자열 형태로 넣어주면 문자열 왼쪽에 있는 해당 문자를 삭제합니다. 다음은 문자열 왼쪽의 ,(콤마)와 .(점)을 삭제합니다. 단, 여기서는 공백을 넣지 않았으므로 공백은 그대로 둡니다.
>>> ', python.'.lstrip(',.') ' python.'
24.1.11 오른쪽의 특정 문자 삭제하기
rstrip('삭제할문자들')과 같이 삭제할 문자들을 문자열 형태로 넣어주면 문자열 오른쪽에 있는 해당 문자를 삭제합니다. 다음은 문자열 오른쪽의 ,(콤마)와 .(점)을 삭제합니다. 마찬가지로 공백을 넣지 않았으므로 공백은 그대로 둡니다.
>>> ', python.'.rstrip(',.') ', python'
24.1.12 양쪽의 특정 문자 삭제하기
strip('삭제할문자들')과 같이 삭제할 문자들을 문자열 형태로 넣어주면 문자열 양쪽에 있는 해당 문자를 삭제합니다. 다음은 문자열 양쪽의 ,(콤마)와 .(점)을 삭제합니다. 여기서도 공백을 넣지 않았으므로 공백은 그대로 둡니다.
>>> ', python.'.strip(',.') ' python'
참고 | 구두점을
간단하게 삭제하기
string 모듈의 punctuation에는 모든 구두점이 들어있습니다. 다음과 같이 strip 메서드에 string.punctuation을 넣으면 문자열 양쪽의 모든 구두점을 간단하게 삭제할 수 있습니다.
>>> import string >>> ', python.'.strip(string.punctuation) ' python' >>> string.punctuation '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
만약 공백까지 삭제하고 싶다면 string.punctuation에 공백 ' '을 연결해서 넣어주면 되겠죠?
>>> ', python.'.strip(string.punctuation + ' ') 'python'
물론 메서드 체이닝을 활용해도 됩니다.
>>> ', python.'.strip(string.punctuation).strip() 'python'
24.1.13 문자열을 왼쪽 정렬하기
이번에는 문자열에 공백을 넣어서 원하는 위치에 정렬하는 방법을 알아보겠습니다.
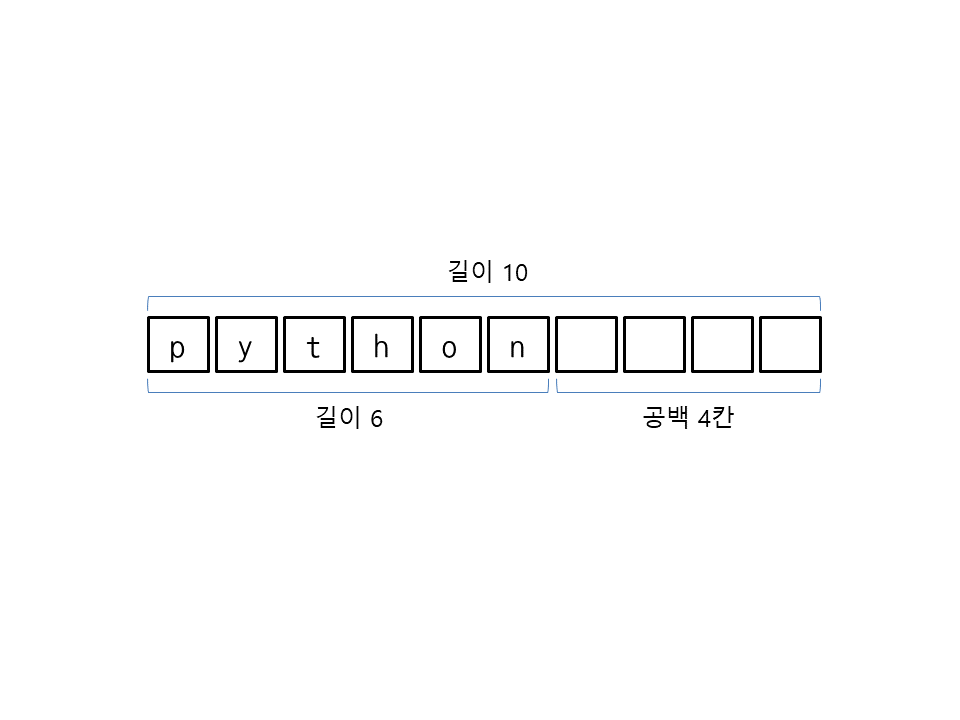
ljust(길이)는 문자열을 지정된 길이로 만든 뒤 왼쪽으로 정렬하며 남는 공간을 공백으로 채웁니다(l은 왼쪽(left)을 의미). 다음은 문자열 'python'의 길이를 10으로 만든 뒤 왼쪽으로 정렬하고 남는 공간을 공백 4칸으로 채웁니다.
>>> 'python'.ljust(10) 'python '
24.1.14 문자열을 오른쪽 정렬하기
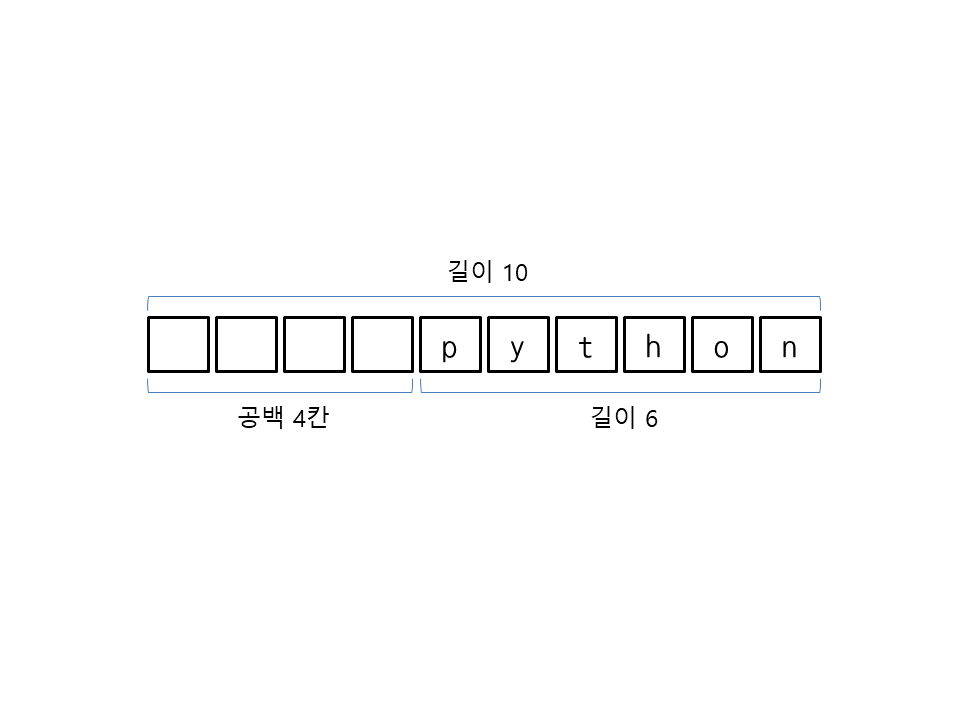
rjust(길이)는 문자열을 지정된 길이로 만든 뒤 오른쪽으로 정렬하며 남는 공간을 공백으로 채웁니다(r은 오른쪽(right)을 의미). 다음은 문자열 'python'의 길이를 10으로 만든 뒤 오른쪽으로 정렬하고 남는 공간을 공백 4칸으로 채웁니다.
>>> 'python'.rjust(10) ' python'
24.1.15 문자열을 가운데 정렬하기
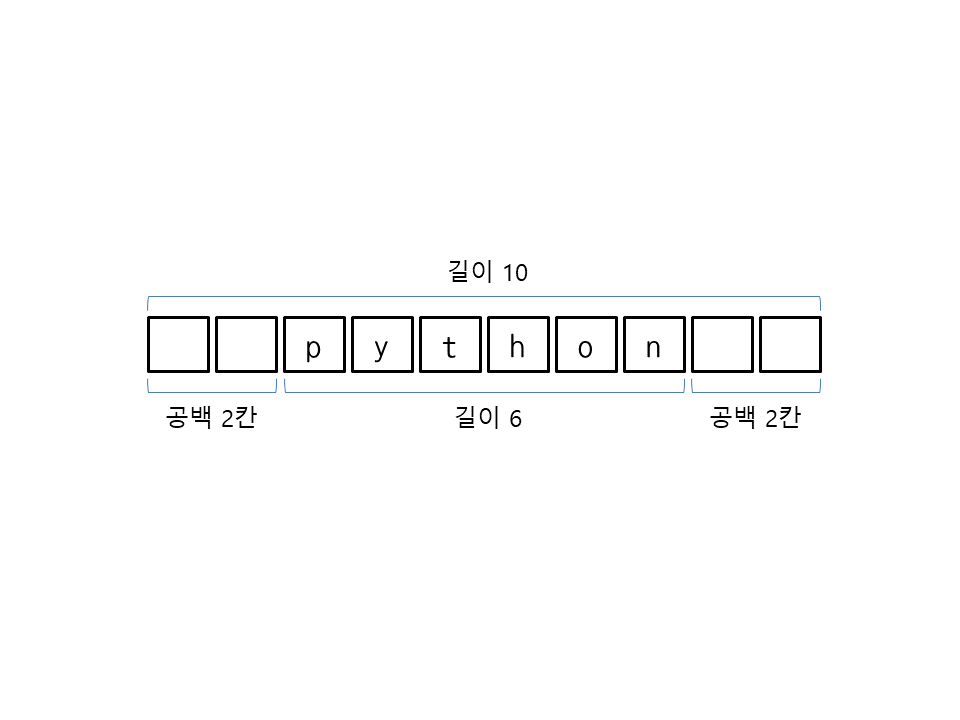
center(길이)는 문자열을 지정된 길이로 만든 뒤 가운데로 정렬하며 남는 공간을 공백으로 채웁니다. 다음은 문자열 'python'의 길이를 10으로 만든 뒤 가운데로 정렬하고 양 옆의 남는 공간을 공백 2칸씩 채웁니다.
>>> 'python'.center(10) ' python '
만약 가운데로 정렬했을 때 전체 길이와 남는 공간이 모두 홀수가 된다면 왼쪽에 공백이 한 칸 더 들어갑니다. 예를 들어 길이가 6인 'python'을 11로 가운데 정렬하면 5가 남아서 왼쪽에 공백 3칸, 오른쪽에 공백 2칸이 들어갑니다.
>>> 'python'.center(11) ' python '
24.1.16 메서드 체이닝
이렇게 문자열 메서드는 처리한 결과를 반환하도록 만들어져 있습니다. 따라서 메서드를 계속 연결해서 호출하는 메서드 체이닝이 가능합니다. 메서드 체이닝은 메서드를 줄줄이 연결한다고 해서 메서드 체이닝(method chaining)이라 부릅니다.
다음은 문자열을 오른쪽으로 정렬한 뒤 대문자로 바꿉니다.
>>> 'python'.rjust(10).upper() ' PYTHON'
사실 문자열을 입력받을 때 자주 사용했던 input().split()도 input()이 반환한 문자열에 split을 호출하는 메서드 체이닝입니다.
24.1.17 문자열 왼쪽에 0 채우기
지금까지 문자열을 정렬하면서 남는 공간에 공백을 채웠죠? 파이썬을 사용하다 보면 문자열 왼쪽에 0을 채워야 할 경우가 생깁니다.
zfill(길이)는 지정된 길이에 맞춰서 문자열의 왼쪽에 0을 채웁니다( zero fill을 의미). 단, 문자열의 길이보다 지정된 길이가 작다면 아무것도 채우지 않습니다. 보통 zfill은 숫자를 일정 자릿수로 맞추고 앞자리는 0으로 채울 때 사용합니다.
>>> '35'.zfill(4) # 숫자 앞에 0을 채움 '0035' >>> '3.5'.zfill(6) # 숫자 앞에 0을 채움 '0003.5' >>> 'hello'.zfill(10) # 문자열 앞에 0을 채울 수도 있음 '00000hello'
24.1.18 문자열 위치 찾기
이번에는 문자열의 위치를 찾는 방법을 알아보겠습니다.
find('찾을문자열')은 문자열에서 특정 문자열을 찾아서 인덱스를 반환하고, 문자열이 없으면 -1을 반환합니다. find는 왼쪽에서부터 문자열을 찾는데, 같은 문자열이 여러 개일 경우 처음 찾은 문자열의 인덱스를 반환합니다. 여기서는 'pl'이 2개 있지만 왼쪽에서 처음 찾은 'pl'의 인덱스 2를 반환합니다.
>>> 'apple pineapple'.find('pl') 2 >>> 'apple pineapple'.find('xy') -1
24.1.19 오른쪽에서부터 문자열 위치 찾기
rfind('찾을문자열')은 오른쪽에서부터 특정 문자열을 찾아서 인덱스를 반환하고, 문자열이 없으면 -1을 반환합니다(r은 오른쪽( right)을 의미). 같은 문자열이 여러 개일 경우 처음 찾은 문자열의 인덱스를 반환합니다. 여기서는 'pl'이 2개 있지만 오른쪽에서 처음 찾은 'pl'의 인덱스 12를 반환합니다.
>>> 'apple pineapple'.rfind('pl') 12 >>> 'apple pineapple'.rfind('xy') -1
24.1.20 문자열 위치 찾기
find, rfind 이외에도 index, rindex로 문자열의 위치를 찾을 수 있습니다.
index('찾을문자열')은 왼쪽에서부터 특정 문자열을 찾아서 인덱스를 반환합니다. 단, 문자열이 없으면 에러를 발생시킵니다. index도 같은 문자열이 여러 개일 경우 처음 찾은 문자열의 인덱스를 반환합니다.
>>> 'apple pineapple'.index('pl') 2
24.1.21 오른쪽에서부터 문자열 위치 찾기
rindex('찾을문자열')은 오른쪽에서부터 특정 문자열을 찾아서 인덱스를 반환합니다(r은 오른쪽(right)을 의미). 마찬가지로 문자열이 없으면 에러를 발생시키며 같은 문자열이 여러 개일 경우 처음 찾은 문자열의 인덱스를 반환합니다.
>>> 'apple pineapple'.rindex('pl') 12
24.1.22 문자열 개수 세기
count('문자열')은 현재 문자열에서 특정 문자열이 몇 번 나오는지 알아냅니다. 여기서는 'pl'이 2번 나오므로 2가 반환됩니다.
>>> 'apple pineapple'.count('pl') 2