42.2 N-gram 만들기
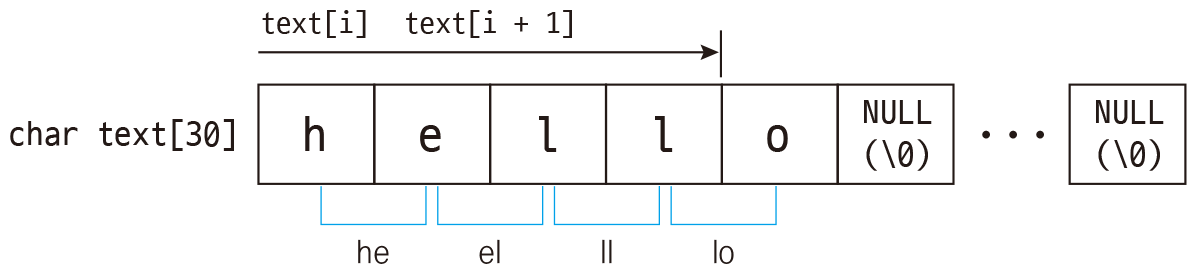
N-gram은 문자열에서 N개의 연속된 요소를 추출하는 방법입니다. 만약 "Hello"라는 문자열을 문자(글자) 단위 2-gram으로 추출하면 다음과 같이 됩니다.
He el ll lo
즉, 문자열의 처음부터 문자열 끝까지 한 글자씩 이동하면서 2글자를 추출합니다. 3-gram은 3글자, 4-gram은 4글자를 추출하겠죠?
이제 C 언어에서 문자 단위 2-gram을 출력해보겠습니다.
2_gram_character.c
#include <stdio.h> #include <string.h> int main() { char text[30] = "Hello"; int length; length = strlen(text); // 문자열의 길이를 구함 // 2-gram이므로 문자열의 끝에서 한글자 앞까지만 반복함 for (int i = 0; i < length - 1; i++) { printf("%c%c\n", text[i], text[i + 1]); // 현재 문자와 그다음 문자 출력 } return 0; }
실행 결과
He el ll lo
생각보다 간단하죠? 2-gram이므로 문자열의 끝에서 한 글자 앞까지만 반복하면서 현재 문자와 바로 그다음 문자 두 글자씩 출력합니다.
만약 3-gram이라면 조건식은 i < length - 2와 같이 되고, 문자열 끝에서 두 글자 앞까지 반복하면 됩니다. 문자열을 출력할 때는 printf("%c%c%c\n", text[i], text[i + 1], text[i + 2]);가 되겠죠? 여기서 문자열의 끝까지 반복하면 text[i + 1], text[i + 2]는 문자열의 범위를 벗어난 접근을 하게 되므로 주의해야 합니다.
글자 단위 N-gram이 있다면 단어 단위 N-gram도 있겠죠? 다음은 문자열을 공백으로 구분하여 단어 단위 2-gram을 출력합니다. 예를 들어 "this is c language"는 "this is", "is c", "c language"가 됩니다.
2_gram_word.c
#define _CRT_SECURE_NO_WARNINGS // strtok 보안 경고로 인한 컴파일 에러 방지 #include <stdio.h> #include <string.h> int main() { char text[100] = "this is c language"; char *tokens[30] = { NULL, }; // 자른 문자열의 포인터를 보관할 배열, NULL로 초기화 int count = 0; // 자른 문자열 개수 char *ptr = strtok(text, " "); // " " 공백 문자를 기준으로 문자열을 자름, 포인터 반환 while (ptr != NULL) // 자른 문자열이 나오지 않을 때까지 반복 { tokens[count] = ptr; // 문자열을 자른 뒤 메모리 주소를 문자열 포인터 배열에 저장 count++; // 인덱스 증가 ptr = strtok(NULL, " "); // 다음 문자열을 잘라서 포인터를 반환 } // 2-gram이므로 배열의 마지막에서 요소 한 개 앞까지만 반복함 for (int i = 0; i < count - 1; i++) { printf("%s %s\n", tokens[i], tokens[i + 1]); // 현재 문자열과 그다음 문자열 출력 } return 0; }
실행 결과
this is is c c language
단어 단위 2-gram도 간단합니다. strtok 함수로 text를 자른 뒤 각 단어들을 tokens 배열에 넣습니다.
char *ptr = strtok(text, " "); // " " 공백 문자를 기준으로 문자열을 자름, 포인터 반환 while (ptr != NULL) // 자른 문자열이 나오지 않을 때까지 반복 { tokens[count] = ptr; // 문자열을 자른 뒤 메모리 주소를 문자열 포인터 배열에 저장 count++; // 인덱스 증가 ptr = strtok(NULL, " "); // 다음 문자열을 잘라서 포인터를 반환 }
2-gram이므로 tokens 배열의 마지막에서 요소 한 개 앞까지만 반복하면서 현재 문자열과 그다음 문자열을 출력하면 됩니다.
// 2-gram이므로 배열의 마지막에서 요소 한 개 앞까지만 반복함 for (int i = 0; i < count - 1; i++) { printf("%s %s\n", tokens[i], tokens[i + 1]); // 현재 문자열과 그다음 문자열 출력 }
읽을거리 | N-gram의 활용
4-gram을 쓰면 picked, picks, picking에서 pick만 추출하여 단어의 빈도를 세는데 이용됩니다. 이런 특성 때문에 검색엔진, 빅데이터, 법언어학 분야에서 주로 활용됩니다.
해리포터의 작가 조앤 롤링은 가명으로 <더 쿠쿠스 콜링>이라는 소설을 출간한 적이 있었습니다. 재미있는 점은 <더 쿠쿠스 콜링>의 작가가 조앤 롤링이라는 것을 밝혀내는데 N-gram을 비롯하여 다양한 기법이 동원되었습니다. 즉, 사람마다 사용하는 문장에 패턴이 있지요. 그래서 같은 의미라 하더라도 사람마다 단어 선택이 다르다는 것을 통계적으로 분석해낸 사례입니다.
-
조앤 롤링을 고백하게 만든 기술, 법언어학:
http://yoonjiman.net/2013/07/23/how-forensic-linguistics-outed-j-k-rowling/
지금까지 회문 판별과 N-gram을 만들어보았는데 소스 코드가 조금 복잡했습니다. 여기서는 문자열의 인덱스를 다루는 방법만 신경쓰면 됩니다.